
Capítulo 2 Guía para una encuesta
En este capítulo se presenta el esquema lógico que debería seguir un relevamiento de alojamientos turísticos, desde el momento en que se plantean los objetivos hasta la obtención de los resultados finales. Estos pasos son, en definitiva, los mismos que se plantean en cualquier tipo de investigación socio-económica, pero por cuestiones de practicidad se optó por enfocarlos a los relevamientos de alojamientos. Cabe indicar que si bien se presentan las etapas de una investigación como una secuencia lógica, en la práctica estas etapas permanecen en diálogo constante.
2.1 Definición de los objetivos de investigación
En primer lugar, una encuesta de alojamientos turísticos (así como cualquier investigación) debe iniciarse con el planteo de los objetivos, entendiéndose a los mismos como los resultados a los que se pretende arribar mediante la investigación.
Los objetivos, a su vez, se subdividen en objetivos generales y específicos. Estos últimos constituyen propósitos específicos que se desprenden del propósito general del estudio. Por ejemplo, el objetivo general de un relevamiento hotelero puede ser conocer el nivel de actividad de los alojamientos turísticos, del que pueden desprenderse objetivos específicos como:
estimar la tasa de ocupación en plazas y habitaciones;
conocer la cantidad de viajeros alojados en establecimientos hoteleros y para-hoteleros;
cuantificar la cantidad de pernoctes registrados en establecimientos hoteleros y para-hoteleros;
etc.
Es importante destacar que los objetivos deben ser claros, para así evitar desviaciones en el proceso de investigación, y viables, es decir, susceptibles de ser alcanzados. Adicionalmente, los objetivos planteados deben ser coherentes entre sí, ya sea en relación al objetivo general como con otros objetivos específicos.
En la mayoría de los operativos provinciales, el objetivo primordial de la encuesta es conocer la tasa de ocupación hotelera en plazas y/o habitaciones y la cantidad de viajeros que recibió la provincia, departamento y/o municipio durante un período determinado (mes, año, temporada estival o temporada invernal). Cabe mencionar que, a pesar de pretenderse estimar indicadores provinciales, en muchas ocasiones la cobertura geográfica no alcanza a todas las localidades de la provincia ni está diseñada de modo tal que sea representativa de toda la provincia. En tales casos, debe tenerse en cuenta que las estimaciones se limitan a esas localidades relevadas y que, si la decisión fuese realizar un análisis estrictamente provincial, tales resultados deben expandirse a toda la provincia, mediante los procedimientos correspondientes.
2.2 Definición de la población bajo estudio y las unidades de análisis
Ligada al planteamiento del propósito inicial de la investigación se encuentra la definición de cuál será la población9 o universo bajo estudio, entendiendo a ésta última como al conjunto de elementos que pretenden estudiarse. Definir la población bajo estudio implica tres pasos fundamentales:
- Establecer cuáles serán las unidades de análisis, es decir, los sujetos o elementos que serán objeto de estudio. En los relevamientos de alojamientos turísticos, las unidades de análisis pueden ser los establecimientos, las habitaciones y/o las plazas. Por ejemplo, si se contabilizan los turistas alojados en los establecimientos, las unidades de análisis serán los mismos establecimientos. Si se estiman la cantidad o porcentaje de plazas ocupadas, las unidades de análisis serán las plazas. Por último, si se calculan la cantidad o porcentaje de habitaciones ocupadas, las unidades de análisis serán las habitaciones. Un mismo relevamiento puede tener varias unidades de análisis, ya que si, por ejemplo, se realizarán todas las estimaciones mencionadas previamente, las unidades serán tanto los establecimientos, como las plazas y habitaciones. Las unidades de análisis deben ser congruentes con los objetivos de estudio. En este sentido, a mayor claridad de los objetivos, mayor será la probabilidad de contar con unidades de análisis coherentes con ellos.
- Definir la cobertura geográfica del relevamiento. En otras palabras, esto significa situar geográficamente a las unidades de análisis. La cobertura geográfica puede ser toda una provincia o algunas localidades de una provincia (por ejemplo, las que cuentan con mayor cantidad de plazas disponibles) o todo el ejido municipal, etc.
- Delimitar temporalmente el estudio, lo que significa establecer el período al cuál estarán referidos los resultados (el cuándo). En este sentido, las mediciones pueden ser continuas, puntuales o específicas. Las mediciones continuas se realizan sistemática e ininterrumpidamente y suelen tener una cobertura total a lo largo de un año, independientemente de la periodicidad de los relevamientos (diario, semanal, quincenal, mensual, etc). Por otro lado, las mediciones puntuales, si bien son sistemáticas, se llevan a cabo en determinadas fechas (temporada alta y fines de semana largos, por ejemplo). Por último, las mediciones específicas suelen realizarse esporádicamente o por única vez, respondiendo a objetivos o situaciones particulares (por ejemplo, un evento o festividad de realización única).
Tomando en cuenta todo lo dicho, la población bajo estudio de un relevamiento de alojamientos turísticos podría estar constituida por todos los establecimientos (y sus correspondientes habitaciones y plazas) de las localidades más grandes (en términos de cantidad de plazas) de la provincia X, durante todo el año (es decir, en forma continua). Otro ejemplo podría plantear una población conformada por todos los establecimientos (y sus correspondientes habitaciones y plazas) inscriptos en la Secretaría de Turismo de la Provincia X, situados en todas las localidades de la jurisdicción provincial, durante las temporadas de verano, invierno y fines de semana largos.
2.3 ¿Censo o Muestra?
Una vez establecido el universo bajo estudio (unidades de análisis, cobertura geográfica y temporal) es preciso definir el tipo de investigación a realizar, esto es si se abordará a todas y cada una de las unidades de la población bajo estudio o bien a una porción de la misma. En el primer caso se trata de un estudio de carácter censal, mientras que la segunda opción se refiere a un estudio por muestreo.
Si la elección fuese encarar una investigación que abarque a todas las unidades de la población, resulta necesario analizarla viabilidad de este alcance, en términos de costo y tiempo. En efecto, un censo insume más tiempo y representa mayores costos en relación a una encuesta por muestreo. Si se optase por realizar un estudio por muestreo, en tanto, debe tenerse presente que una muestra es un conjunto de unidades a partir de la cual se pretenden realizar inferencias sobre la población de origen. Por lo tanto, no cualquier subgrupo de la población podrá constituir una muestra cuyos resultados sean extrapolables a la totalidad de la población objeto.
En este sentido, si la decisión fuese realizar un estudio por muestreo, deben considerarse los siguientes puntos:
la construcción de un marco muestral;
cuál será el procedimiento de selección de la muestra (o qué tipo de muestreo se llevará a cabo);
cuál será el tamaño de muestra apropiado para dar cuenta de los objetivos de la investigación.
Si bien una primera impresión podría considerar al censo como la opción más viable y sencilla, el mismo, además de sus implicancias en términos de costo y tiempo, puede ocasionar una serie de situaciones que podrían evitarse con una muestra. Por ejemplo, debido a la magnitud de un operativo censal, es probable que quienes ejecutan el relevamiento resignen calidad en las respuestas o en la forma de relevar en pos de terminar en el tiempo previsto el trabajo de campo. Este tipo de error es menos factible de presentarse en una encuesta por muestreo donde, si bien el resultado tendrá asociado un margen de error estadístico (conocido), la menor cantidad de casos a cubrir hace posible una mayor calidad en el registro de los datos. Por su parte, una muestra puede llevar implícito el riesgo de obtener resultados que no reflejen el comportamiento de la población. Sin embargo, si la muestra ha sido seleccionada con criterios estadísticos, será posible estimar el margen de error y el nivel de confianza de las estimaciones.
Recomendación: Como regla general, puede sostenerse que cuando el objetivo sea estudiar un pequeño número de unidades (por ejemplo, una localidad con menos de 30 establecimientos) lo más conveniente sea la realización de un estudio censal. En cambio, cuando el número de unidades sea elevado y/o se pretendan integrar varias localidades para obtener representatividad provincial, lo aconsejable es encarar un estudio por muestra.
La EOH cuenta con una muestra mensual de aproximadamente 3 mil establecimientos hoteleros y parahoteleros en las 49 localidades relevadas. El diseño es de tipo estratificado en grupos de establecimientos según categorías, con un método de selección de probabilidad proporcional a la cantidad de plazas. Es decir, los establecimientos de cada una de las localidades relevadas por la EOH tienen asociados una probabilidad de seleccion en función de las plazas que disponen dentro de cada estrato; aquellos hoteles con mayor cantidad de plazas ofrecidas tendrá mayor probabilidad de ser seleccionado en la muestra. Cabe aclarar, que los hoteles de 4 y 5 estrellas son de “inclusión forsoza” , es decir son censados todos. De esta manera, la EOH a partir de los datos muestrales expandidos brinda información mensual de 49 localidades, de 7 regiones turísticas y para el total nacional. Ver +: Doc metodológico (INDEC).
2.4 Padrón de establecimientos de alojamiento turísticos
Un requisito fundamental en todo relevamiento de alojamientos turísticos, sea censal o muestral, es contar con un padrón o listado que contenga la totalidad de los establecimientos de alojamientos que cumplan, como mínimo, con las condiciones definidas para la población o universo bajo estudio. En efecto, dicho padrón operará como marco de referencia para la identificación de las unidades a ser relevadas. En el caso particular de los estudios por muestreo, el padrón de establecimientos constituye el marco muestral desde el cual se seleccionarán los establecimientos que conformarán la muestra a ser relevada.
A priori, la definición de la población o universo bajo estudio debería ser un paso previo a la selección del padrón. Sin embargo, en la práctica, en muchas ocasiones el alcance del padrón suele condicionar la delimitación del universo o población bajo estudio. De este modo, la población o universo ya no se desprende únicamente de los objetivos de estudio, sino que también depende de la información disponible en el padrón o listado.
En las provincias, departamentos y municipios, los alcances de los relevamientos son diversos, debido tanto a los objetivos de estudio propios de cada jurisdicción como a la cobertura del padrón.
En relación a los objetivos, la mayoría de las jurisdicciones relevan únicamente a los establecimientos con habilitación comercial (dejando fuera de objeto a los establecimientos no habilitados), en tanto que otras incluyen también a los establecimientos con habilitación en trámite. Asimismo, unas pocas provincias, departamentos y/o municipios también cubren a los establecimientos sin habilitación comercial.
En lo que respecta a los padrones (o listados) de los que disponen las entidades de turismo de los distintos niveles jurisdiccionales, se suelen presentar las siguientes situaciones, que dependen en gran medida del proceso de habilitación y registro de los establecimientos de alojamiento turístico:
Padrones o listados municipales: Debido a que la habilitación comercial de los establecimientos de alojamiento se efectúa a nivel municipal, los listados de los que disponen las entidades municipales abarcan generalmente a la totalidad de los establecimientos habilitados.
Padrones o listados provinciales: Como regla general, todos los establecimientos habilitados comercialmente a nivel municipal deberían estar registrados en los padrones de las entidades provinciales de turismo, ya que su posterior registro en la entidad provincial es un procedimiento obligatorio. Sin embargo, a menudo esto no ocurre, razón por la cual los registros provinciales de establecimientos, salvo excepciones, suelen tener menor cantidad de establecimientos que los registros o listados municipales. Por tanto, suelen encontrarse discrepancias entre los padrones de los diferentes municipios que integran una provincia y el correspondiente registro provincial. En relación a este punto, hay algunas provincias que se encargan de completar su padrón provincial con los establecimientos que están presentes en el listado municipal, pero que no figuran en el listado oficial provincial. Sin embargo, estos casos son excepcionales.
Como consecuencia de estas situaciones, aquellas provincias que relevan (en su encuesta o relevamiento de alojamientos turísticos) únicamente aquellos establecimientos presentes en su registro provincial, no solo estarán excluyendo de su objeto de estudio a los establecimientos no habilitados, o con habilitación en trámite, sino que también estarán dejando fuera de análisis a aquellos establecimientos que, aun contando con habilitación comercial, no están asentados en los registros provinciales. En cambio, aquellas provincias que centralizan datos producidos por los municipios es posible que cuenten con una cobertura mayor de establecimientos habilitados, ya que los establecimientos relevados son los que figuran en los registros municipales; sin embargo, estarán dejando de lado a los establecimientos que no cuentan con habilitación comercial, y por tanto su cobertura no es total.
Una consecuencia no menor de las diferencias de cobertura de los padrones o listados de las diferentes provincias y municipios es la escasa comparabilidad interprovincial (e intermunicipal) de los resultados provenientes de este tipo de relevamientos.
Recomendación: Teniendo todo esto en cuenta, si se pretende tener una dimensión total del nivel de actividad de los establecimientos de alojamiento turístico, así como de la cantidad de viajeros estimados a partir de este tipo de relevamientos, es preciso tener una cobertura de establecimientos lo más amplia posible. En este sentido, en primer lugar, si bien los establecimientos no habilitados desarrollan su actividad obviando requerimientos legales, a los fines estadísticos es de relevancia incorporar a estos establecimientos dentro de la población bajo estudio. En segundo lugar, ya dentro de los establecimientos habilitados, es recomendable que los registros provinciales sean ampliados, tomando como referencia los registros municipales, que en general cuentan con mayor cantidad de establecimientos que los provinciales.
Por otro lado, los procedimientos de actualización también contribuyen a ampliar la cobertura de los padrones y, por tanto, de los relevamientos o encuestas de alojamientos turísticos. Por ello, se recomienda desarrollar acciones para actualizar los padrones con una frecuencia adecuada.
Mantener actualizados los padrones supone:
Tener registradas las altas y bajas de los establecimientos o lugares de alojamiento, y que esas situaciones sean fácilmente identificables al leer el padrón. Por ejemplo, si un establecimiento X cierra definitivamente, es aconsejable mantener el nombre del mismo en el padrón y agregarle alguna indicación que dé cuenta de su situación actual. Si, citando otro ejemplo, un establecimiento cierra sus puertas en forma temporaria, también es recomendable dejarlo asentado en el padrón, en forma similar a como se haría en los casos de cierre definitivo.
Para cada establecimiento o lugar de alojamiento, detallar la cantidad de habitaciones y/o unidades, y plazas disponibles. En este punto es preciso considerar que la disponibilidad en los establecimientos puede ser variable a lo largo de un año calendario, como consecuencia de la estacionalidad de la actividad turística u otros factores (por ejemplo, refacciones). Por ejemplo, puede ocurrir que durante las temporadas bajas, algunos establecimientos decidan sacar de la oferta algunas habitaciones (y por ende plazas) dada la menor demanda potencial de alojamiento durante dicho período o bien colocar una menor cantidad de camas en las habitaciones (manteniendo la cantidad de habitaciones pero disminuyendo las plazas disponibles). En este sentido, las jurisdicciones que actualizan con una alta frecuencia sus padrones (por ejemplo, mensualmente), probablemente tengan registradas estas situaciones. En cambio, aquellas jurisdicciones que actualicen el listado con menor frecuencia (por ejemplo, al inicio de cada temporada, anualmente, o, incluso únicamente al momento de la inscripción del establecimiento en el padrón o listado) es probable que no puedan tener una detección precisa de la variabilidad en la disponibilidad. A los fines de contar con padrones que reflejen lo más preciso posible la disponibilidad real de los establecimientos, lo recomendable es actualizar los padrones en forma continua a lo largo de todo el año. Una forma de lograr una actualización continua es solicitando la disponibilidad de plazas y habitaciones en el mismo relevamiento de ocupación de alojamientos. Por otro lado, es preciso que, en cada establecimiento listado, la cantidad de plazas registrada sea coherente con la cantidad de habitaciones registrada (p.e, la cantidad de plazas disponibles no puede ser inferior a la cantidad de habitaciones o unidades disponibles).
Ligado al aspecto anterior, para el caso de padrones conformados por establecimientos (o lugares de alojamiento) habilitados y no habilitados, es aconsejable que se explicite la situación en que se encuentran. Asimismo, si los padrones incluyen a los establecimientos (o lugares de alojamiento) con habilitación en trámite, es recomendable indicar cuál es el tiempo aproximado que lleva completar el trámite de habilitación. De este modo, si un establecimiento figura en situación de “habilitación en trámite” por un tiempo extendido, sería posible conjeturar si esa situación se debe a una demora administrativa o a un problema de actualización del padrón.
Las implicancias planteadas representan un estado ideal de actualización, que en la situación particular de cada provincia/departamento/municipio pueden ser más o menos alcanzables. Lógicamente, padrones actualizados garantizan universos más completos y muestras más acordes a la población de que son extraídas, y por tanto, resultados de ocupación del sector con mayor robustez y representatividad.
2.5 Estudios por muestreo. Tipos de muestreo
Existen distintos tipos de muestreo. Un primer criterio de clasificación los distingue en probabilísticos y no probabilísticos. En el primer tipo de muestreo se tiene conocimiento de cada una de las unidades que conforman la población bajo estudio (y de la que se extraerá la muestra), ya que se dispone de algún documento u otro tipo de material que da cuenta de la misma. A su vez, al conocer a todas las unidades que conforman la población, también se conoce la probabilidad de cada una de ellas de ser seleccionadas para formar parte de la muestra. En cambio, en el muestreo no probabilístico no se dispone de información acerca de la población bajo estudio y, por ende, tampoco de las probabilidades de selección de cada unidad.
Teniendo en cuenta esta primera clasificación, y en caso que se haya optado por realizar un estudio por muestreo, el paso siguiente consiste en decidir qué tipo de muestreo se seguirá: probabilístico o no probabilístico.
2.5.1 Muestreo no probabilístico
El muestreo no probabilístico suele utilizarse cuando no se dispone de información acerca de la población bajo estudio y, por lo tanto, de los elementos que integrarán la muestra. Esta situación es muy habitual en las encuestas de demanda turística y perfil del visitante, en las que la obtención de un marco de muestreo adecuado presenta grandes dificultades. En los relevamientos de alojamientos turísticos, en cambio, los padrones de establecimientos ofrecen un listado con la identificación y otras informaciones de todos (o casi todos) los establecimientos que constituyen la población de estudio. Por lo tanto, es posible calcular la probabilidad de selección de cada establecimiento y, en consecuencia, sortear muestras probabilísticas.
Si bien en los relevamientos de alojamientos turísticos los padrones hacen posible seleccionar muestras probabilísticas, en el trabajo de campo, la misma puede devenir en no probabilística. Para comprender mejor esta situación, se cita el siguiente ejemplo. En un operativo se confecciona una muestra probabilística compuesta solamente por hoteles, clasificados en 5 grupos según categoría (estrellas), es decir, en hoteles de 5, 4, 3, 2 y 1 estrellas. En la misma, el peso de cada grupo de hoteles es proporcional al observado en la población; a su vez, las unidades de cada grupo son seleccionadas aleatoriamente. Durante el trabajo de campo, por falta de colaboración de los informantes, no se logra obtener información de varios hoteles de 3 estrellas; sin embargo, no se ejecuta ningún procedimiento de reemplazo de los establecimientos con no respuesta. Debido a ello la muestra se transformará en no probabilística, dado que, a causa de la no respuesta, las probabilidades de selección de los establecimientos dentro del grupo de 3 estrellas se han distorsionado. Esto no implica que la no respuesta de algunas unidades transformen a una muestra probabilística en no probabilística, pero sí que la magnitud de la no respuesta debe ubicarse dentro de parámetros razonables y que deben realizarse procedimientos -durante el trabajo de campo y después del mismo- para corregir los posibles sesgos que la no respuesta podría traer aparejados.
Cabe mencionar que la sola presencia de un padrón o registro de establecimientos no garantiza necesariamente que la muestra que de él se extraiga sea probabilística. Para que la muestra sea probabilística, en efecto, es preciso seguir algunos pasos, que serán descritos en los sub-apartados siguientes. Más aún, a pesar de la existencia de un padrón, puede ocurrir que alguna entidad de turismo decida seleccionar una muestra compuesta por los establecimientos cuyos informantes tengan mayor predisposición a responder. Una selección guiada por este criterio es un ejemplo de muestra no probabilística deliberada como tal.
Si bien el muestreo no probabilístico se constituye en una alternativa posible, el mismo presenta algunas desventajas en relación al probabilístico:
La muestra que de él resulta puede estar sesgada (es decir, puede haber sobre-representación de algún grupo y/o sub-representación de otro grupo).
No es posible conocer el grado de precisión y el nivel de confianza de las estimaciones (estos conceptos serán desarrollados en los siguientes sub-apartados).
Vinculado al punto anterior, no es posible generalizar los resultados de la muestra a la población sino que solo serán representativos de los elementos incluidos en la muestra.
Recomendación: Más allá de las desventajas, el muestreo no probabilístico se presenta como una alternativa útil cuando no se cuenta con un marco muestral del cual seleccionar las unidades que conformarán la muestra. Sin embargo, tal como se mencionó previamente, esto no es algo que suceda en los relevamientos de alojamientos turísticos, ya que en todos los casos se cuenta con un marco de muestreo, por lo tanto no cabe duda de que este tipo de operativos deben contemplar las herramientas que la estadística y el muestreo brindan para construir estudios robustos y representativos.
Para cada localidad (dominio muestral) de la EOH, se diseña una muestra estratificada. Los estratos se construyen teniendo en cuenta la categoría de cada uno de los hoteles del marco. El tamaño muestral de cada uno de los estratos en cada localidad relevada se adjudica a través de una asignación óptima (a diferencia de la asignación proporcional, en este caso, la muestra recogerá más hoteles de aquellos estratos que tengan más variabilidad). Luego, teniedo los correspondientes tamaños para cada estrato, la selección de los hoteles será a través de un muestreo con probabilidad proporcional a la cantidad de plazas disponibles. Es decir, los hoteles con mayor oferta de plazas tendrá mayor probabilidad de selección para conformar la muestra de ese estrato.
2.5.2 Muestreo probabilístico
A diferencia del muestreo no probabilístico, las muestras probabilísticas son aquellas en las que:
todas los elementos de la población tienen alguna probabilidad de ser seleccionados, siendo dicha probabilidad distinta a cero,
las probabilidades son conocidas de antemano, es decir, previo al sorteo de las unidades que finalmente compondrán la muestra.
En este tipo de muestras, la selección de los elementos que la integrarán sigue un procedimiento aleatorio, es decir, sin intervención de la subjetividad del investigador o de otras personas que puedan estar involucradas en esta etapa.
Cabe mencionar que únicamente las muestras probabilísticas son las que hacen posible la inferencia estadística, esto es, que los resultados obtenidos sean extrapolables a la población objeto de estudio, ya que permiten conocer el nivel de confianza y la precisión de esas estimaciones.
2.5.2.1 Marcos muestrales
Como se adelantó en párrafos anteriores, una condición prácticamente indispensable para poder llevar adelante un proceso probabilístico de selección de la muestra es contar con un marco muestral. Este último, en términos prácticos, es un listado que contiene la totalidad de las unidades que componen la población de estudio y que permite conocer, previo al sorteo (selección aleatoria) de la muestra, la probabilidad de selección de cada elemento.
En las encuestas de alojamientos turísticos, los listados que operan como marco muestral son, como ya se indicó, los padrones o listados de establecimientos de alojamiento.
La EOH cuenta con un marco muestral compuesto por la nómina de todos los establecimientos hoteleros y parahoteleros del país con sus principales características: categoría hotelera, número de habitaciones o unidades disponibles, número de plazas disponibles, servicios ofrecidos, etc. Todos los años este padrón se actualiza a través de la incorporación de los nuevos establecimientos que aparecen en las localidades relevadas y la baja de los establecimientos que dejan de existir. A partir de este registro se toman las muestras todos los años y se expanden los resultados de la misma. Cabe aclarar que en el marco solo se consideran los establecimientos que tengan más de 12 plazas o más de 4 habitaciones/unidades.
2.5.2.2 Muestreo aleatorio simple
El muestreo aleatorio simple (MAS) resulta ser el más sencillo de todos, pero, a la vez, el menos utilizado en la práctica de la investigación. No obstante ello, su análisis hace posible la comprensión de otros procedimientos de muestreo más complejos.
Un procedimiento de selección de muestra es aleatorio simple si otorga a cada elemento de la población objeto la misma probabilidad de ser seleccionado. Esta probabilidad de selección está definida por la razón entre n/N (fracción de muestreo), donde n es el tamaño deseado de la muestra y N el tamaño de la población.
Una forma adecuada de seleccionar una muestra con este procedimiento es enumerando a todos los elementos de la población (por ejemplo, a cada establecimiento del padrón de alojamientos habilitados) secuencialmente, desde 1 hasta N. Luego, se debe realizar una selección aleatoria de las unidades10.
2.5.2.3 Muestreo sistemático
El muestreo sistemático (en adelante, MSYS) también asigna a cada elemento de la población idéntica probabilidad de selección (n/N), aunque el procedimiento difiere en relación al MAS.
En primer lugar, al igual que en el MAS, deben numerarse consecutivamente todos los elementos de la población, desde 1 hasta N. En segundo lugar, se procede a calcular la razón entre el tamaño poblacional (N) y el tamaño deseado de la muestra (n), N/n, que es denominado intervalo de selección. Por ejemplo, si la cantidad total de establecimientos de alojamiento en una localidad es de 1.800 y el tamaño de la muestra que se pretende seleccionar es de 180 establecimientos, el intervalo de selección será 10. En tercer lugar, debe seleccionarse un número aleatorio (r) entre 1 y 10, que será el que designe al elemento que dará arranque a la selección (denominado arranque aleatorio). Una vez seleccionada la unidad que ocupa el primer lugar, se debe tomar la siguiente, que está a 10 lugares de la primera (r+10), es decir, la que está en la posición 11. Sucesivamente, debe continuarse con la selección del resto de las unidades, respetando los intervalos de selección (en este ejemplo, 21, 31, 41, etc.).
Una de las ventajas de los MSYS es que permiten ordenar a la población de acuerdo a una variable conocida y relevante para el estudio (por ejemplo, cantidad de habitaciones o plazas, o categoría del establecimiento) y así garantizar una mejor representatividad de la muestra respecto a la población de origen. Esto es posible también, y con mayor rigurosidad, empleando un muestreo aleatorio estratificado por asignación proporcional (el caso más simple de muestreo estratificado, descrito en el apartado Muestreo estratificado). No obstante, el muestreo sistemático con una variable ordenadora es una excelente aproximación al muestreo estratificado y de mayor practicidad.
2.5.2.4 Tamaño de la muestra
Si bien se comenzó el desarrollo sobre muestras probabilísticas con los conceptos de MAS y MSYS, la determinación del tamaño de la muestra es un paso previo a la selección de los elementos que finalmente la conformarán.
El muestreo probabilístico presenta la ventaja de ofrecer fórmulas matemáticas que, con la ayuda de información sobre la población bajo estudio, permiten establecer el tamaño de muestra adecuado para los resultados que pretenden alcanzarse.
Adicionalmente, es necesario mencionar que, a pesar de existir fórmulas que permiten determinar el tamaño de la muestra, el procedimiento total no es “automático” , sino que deben contemplarse una serie de factores y circunstancias que permitirán luego definir cuál es el tamaño de muestra adecuado para el estudio específico.
En primer lugar, no deben perderse de vista los objetivos del estudio y los niveles de desagregación con que se pretende analizar la información (sub-dominios de análisis). En efecto, si el propósito del estudio fuese presentar los resultados abiertos por clase y categoría de los establecimientos, el tamaño final de la muestra debería permitir realizar dichas desagregaciones con casos suficientes para obtener estimaciones robustas.
Adicionalmente, el tamaño de la muestra también depende de con cuánta precisión quiera realizarse la estimación, dado que un estudio por muestra siempre llevará asociado un margen de error estadístico. Que una estimación tenga un margen de error no significa que sea “incorrecta” , sino que indica un rango, a partir del valor puntual obtenido, dentro del cual se encontrará el valor verdadero con un determinado grado de confianza. En otras palabras, el error muestral expresa la distancia máxima que puede haber entre la estimación realizada sobre la muestra y el valor real poblacional (parámetro).
El error estadístico se expresa de diversas maneras, aunque generalmente se presenta como un valor que se suma y se resta a la estimación puntual. Por ejemplo, si un relevamiento arroja que la tasa de ocupación hotelera es del \(75\%\), y a su vez el error es de +/- 3, esto significa que el valor poblacional (verdadero) puede variar entre \(72\%\) y \(78\%\) (dado que el 3 se suma y se resta a la estimación puntual).
El margen de error es un atributo definido por quien lleva a cabo la investigación: cuanto mayor sea la precisión esperada de una estimación, menor debe ser el margen de error a definir. Sin embargo, esto no es gratuito: a menor margen de error pretendido, mayor será el tamaño de la muestra sobre la que se deberá trabajar.
Conviene profundizar algo más en este tema con un ejemplo. Si el relevamiento tuviese como una de sus finalidades principales medir variaciones a lo largo del tiempo, debe considerarse un margen de error adecuado a la sensibilidad del cambio que se procura revelar con la investigación, puesto que desde un punto de vista estricto, puede afirmarse que hubo variaciones cuando los intervalos (estimación +/- margen de error) no se superponen. Así, si se trabaja con un margen de error de 3% y en diciembre de 2012 se obtuvo una tasa de ocupación del \(60\%\)(intervalo \(57\%\)-\(63\%\)) y en diciembre de 2013 la estimación alcanzó al \(62\%\) (intervalo \(59\%\)-\(65\%\)), no puede concluirse que hubo una modificación en la variable estimada, puesto que los intervalos de confianza de los resultados obtenidos se superponen. En otras palabras, un estudio con un margen de error del 3% permitirá afirmar que hubo variaciones estadísticamente significativas sólo cuando las diferencias superen los 6 puntos porcentuales.
Como puede deducirse, al establecer el margen de error con el que se trabajará se debe respetar la profundidad que la investigación requiere, o bien, reducir el alcance de los objetivos de la misma. Si bien siempre es preferible un margen de error más pequeño, lograrlo implica cada vez mayores costos (económicos, humanos, de tiempo), y por tanto es preciso analizar ventajas y desventajas para arribar a la definición a un nivel de error eficiente11.
En cuanto a los condicionantes del tamaño de muestra, éste también depende del nivel de confianza con el que pretendan estimarse los indicadores. Habitualmente, en investigaciones socio-económicas se utilizan niveles de confianza del \(90\%\) o \(95\%\). Un nivel de significación del \(90\%\) indica que, de 100 muestras que se extraigan del universo o población, en 90 de ellas se obtendrán estimaciones que expresarán el rango o intervalo en que se ubica el parámetro poblacional. Un nivel de confianza del \(95\%\), a su vez, indica probabilidades de acierto mayores, ya que de 100 muestras, 95 contendrán el valor del parámetro. Si bien el nivel de confianza también es definido por el investigador y, cuanto mayor sea la confianza definida, mayor será el tamaño de muestra, en este punto se recomienda trabajar con un \(90\%\) de nivel de confianza.
Por último, la dispersión de la población de origen, en función de la variable de estudio más relevante, también influye en el tamaño final que tendrá la muestra. Por dispersión se entiende a la variabilidad que presentan las diferentes unidades de una población en torno a una variable específica. Cuanto mayor sea la dispersión de la población, mayor será el tamaño de muestra necesario. Cabe señalar que en general se desconoce la dispersión en torno a la/s variable/s bajo estudio (dado que se desconoce la magnitud de los valores a estimar). Algunas alternativas que permitirían sortear esta situación podrían ser:
tomar como referencia resultados de estudios previos;
realizar una prueba piloto, que arrojen un resultado posible de la variable a estimar;
suponer la máxima variabilidad posible.
Cabe señalar que existen diferentes fórmulas para determinar el tamaño de muestra, dependiendo de las estimaciones que pretendan realizarse a partir de la misma. Es decir, la fórmula será diferente según se procure estimar promedios, proporciones, totales, etc. En los relevamientos hoteleros, las estimaciones fundamentales que se recomienda realizar son las de cantidad de plazas ocupadas y cantidad de habitaciones/unidades ocupadas, para luego estimar proporciones o porcentajes (proporción multiplicada por 100). Por lo tanto, a priori se recomienda utilizar la fórmula para estimar totales (ya que se estimarán total de plazas o habitaciones/unidades ocupadas).
La fórmula para estimar totales, asumiendo un procedimiento de selección simple al azar (MAS), por ser el más sencillo, y en la que se asume que la población tiene un tamaño conocido (población finita), es:
\(n= (N2^*z2^*σ2)/ [d2+(N2^*z2^* σ2)/N) ]\), donde:
\(n\)= tamaño de la muestra;
\(z\)=valor estándar que depende del nivel de confianza fijado; para un nivel de confianza del \(90\%\), el valor de \(z\) es \(1,645\).
\(d\)=margen de error aceptado;
\(σ2\)=varianza de la población en torno a la variable de análisis. La varianza es una medida de la dispersión o variabilidad de la población alrededor de dicha variable. Por ejemplo, si la variable de análisis es plazas ocupadas, la variabilidad o dispersión depende de los diferentes valores que pueda asumir la variable en los diferentes establecimientos.
\(N\)=tamaño de la población.
Nótese que, entre la información de la que se necesita disponer para determinar el tamaño de la muestra, la más difícil de obtener es la de dispersión o variabilidad de la variable bajo estudio, ya que se supone que su comportamiento es desconocido. De hecho, el estudio por muestreo se estaría realizando justamente para conocer cómo se comporta dicha variable. Sin embargo, en muchas jurisdicciones es probable que se cuente con información de relevamientos previos, de los cuales pueda extraerse esta información. Asimismo, también existe la alternativa de recurrir a los datos de la EOH (del MINTURDEP-INDEC), que podrían aportar información sobre la dispersión de la variable en cuestión. Por último, una alternativa adicional, aunque menos recomendable que las anteriores (pero viable si no se puede optar por las mismas) podría ser emplear la fórmula para estimar proporciones, que también es una de las estimaciones a las que se arribaría, pero con el uso de las cantidades absolutas de plazas ocupadas. Esta fórmula, ante el desconocimiento de la dispersión de la población en torno a la variable de estudio, asume una máxima variabilidad, que equivale a considerar que la proporción a estimar será del 0,5.
La fórmula para estimar proporciones, asumiendo un procedimiento de selección simple al azar (MAS), y suponiendo que la población tiene un tamaño conocido (población finita), es:
\(n\) = \((z2^*p^*q)\) / \([d2 + (z2^*p^*q) / N]\), donde:
\(n\)= tamaño de la muestra;
\(z\)=valor estándar que depende del nivel de confianza fijado; para un nivel de confianza del \(90\%\), el valor de \(z\) es \(1,645\).
\(d\)=margen de error aceptado (\(3\%\)=\(0,03\), \(2\%\)=\(0,02\), etc.);
\(p\)=proporción a estimar (supuesto de máxima variabilidad=\(50\%\)=\(0,5\));
\(q\)=\(1-p\), también por definición \(0,5\) (\(1\)-\(0,5\)=\(0,5\));
\(N\)=tamaño de la población.
2.5.2.5 La representatividad y el azar
En investigación, es habitual referirse a si una muestra es o no “representativa” de la población o universo de la que fue seleccionada. A pesar de su uso frecuente, esta noción sólo tiene un alcance intuitivo, ya que no existe un procedimiento formal que permita medir el grado de representatividad de una muestra.
Sin embargo, a los fines de hacer un uso menos impreciso de este término, podría considerarse que una muestra es representativa cuando reproduce (o se aproxima a) la estructura de la población en torno a una o varias variables. En el caso de las encuestas de alojamientos turísticos, una muestra podría calificarse como representativa si, por ejemplo, en su interior la distribución de los tipos de alojamientos turísticos presenta la misma heterogeneidad que en el padrón.
Por otro lado, es común sostener que un procedimiento de selección al azar garantiza la obtención de una muestra representativa a los efectos de ciertos rasgos de la población (por ejemplo, el “tipo” de alojamientos: hoteles, hosterías, apart hoteles, etc.). Sin embargo, puede ocurrir, aunque no de manera frecuente (esta posibilidad se reduce a medida que se aumenta la muestra), que en una muestra seleccionada mediante MAS un grupo con ciertos rasgos presente en la misma un peso diferente al que tiene en la población. Por ejemplo, en la muestra, los apart hoteles pueden representar un \(8\%\) del total de establecimientos de alojamiento, mientras que en la población el peso es \(15\%\). En este caso, se está ante una situación de sub-representación del segmento apart hoteles; inversamente, también puede producirse una sobre-representación de los apart hoteles en relación a la población de referencia.
Por esta razón, emplear el procedimiento de selección sistemático mediante una variable ordenada es preferible, dado que previene contra casos de “mala suerte” en las unidades seleccionadas. En este sentido, un muestreo aleatorio estratificado por asignación proporcional es aún mejor, pero de difícil cálculo.
2.5.2.6 Muestreo estratificado
Como se adelantó, un procedimiento de selección que permite aproximarse a muestras representativas de la estructura poblacional es el muestreo aleatorio estratificado, dado que intenta reflejar, en la muestra, la composición poblacional en función de determinadas características que se asumen como relevantes para el tema bajo estudio.
Adicionalmente, el muestreo estratificado también responde a otras finalidades:
Disminuir la dispersión general de la variable en estudio, mediante la conformación de grupos (o sub-poblaciones) homogéneos en su interior.
En relación al punto anterior, alcanzar resultados más precisos con un mismo tamaño de muestra. Por ejemplo, si con MAS se alcanzó un tamaño de muestra de 400 casos, que permitirá realizar estimaciones con un margen de error de +/- \(4\%\), mediante el muestreo estratificado es posible obtener resultados con un margen de error inferior a \(4\%\), manteniendo el mismo tamaño de muestra.
Obtener resultados en sub-poblaciones de interés. Por ejemplo, si la variable/s en torno a la/s cual/es se estratifican es/son clase y categoría, y, asimismo, se pretende realizar estimaciones para un grupo específico (p.e., hoteles de 5 estrellas), es recomendable considerar a este grupo como un estrato específico.
La estratificación es un proceso previo a la selección de las unidades que conformarán la muestra, que consiste en clasificar a la población bajo estudio en diferentes grupos o estratos, según características específicas que se supone tienen algún tipo de impacto en el comportamiento de la variable/s de análisis. En el caso específico de los relevamientos de alojamientos, los estratos suelen estar constituidos por “clases de alojamiento” (hotel, apart hotel, bungalow" , etc), “categorías de alojamiento” (estrellas), una combinación entre ambas, o bien, en el caso de estudios de alcance provincial, por distintas localidades, etc.
Estos estratos deben ser lo más homogéneos posible en su interior (es decir, las unidades que lo componen tienen que ser lo más parecidas entre sí) y lo más diferente posible del resto de los estratos (heterogeneidad externa), con el fin de lograr reducir la dispersión general de la variable bajo estudio. Obviamente, la homogeneidad interna y heterogeneidad externa estarán definidas en función de la variable de estratificación.
Es preciso tener presente que para poder estratificar a la población, es necesario tener un conocimiento previo de la misma. Por lo tanto, es indispensable que la información auxiliar que se utilizará para segmentar a la población esté presente en el marco muestral.
Luego de haberse establecido cuáles serán los estratos, se hace necesario determinar el tamaño de cada estrato, que en definitiva son sub-muestras dentro de la muestra total. A este procedimiento se le llama asignación de casos. Si bien existen diversas formas de asignar casos, aquí se presenta el proceso de asignación proporcional, que resulta ser el más sencillo de todos. Asimismo, tiene como ventaja el garantizar que la muestra reproducirá la estructura de la población en función de su distribución entorno a una o más variables. De este modo, se eliminaría el riesgo de una muestra aleatoria simple en la que la “mala suerte” deje por ejemplo a un grupo sin estimar.
2.5.2.6.1 Asignación proporcional
Un paso previo a la asignación de casos es la determinación del tamaño total de la muestra. Una alternativa viable y sencilla es hacerlo mediante muestreo aleatorio simple (MAS), y posteriormente asignar casos a cada estrato.
Una vez establecido el tamaño total de la muestra, se procede a calcular el peso relativo (expresado en porcentaje o proporción) de cada uno de los estratos en la población total. Luego, el porcentaje o proporción correspondiente a cada estrato se multiplica por el tamaño total de la muestra, para obtener el tamaño (o cantidad de casos) de cada estrato. Por ejemplo, se supone que la población fue dividida en 3 estratos, cuyos pesos son 0,2, 0,45 y 0,35. Si el tamaño total de la muestra es de 400 casos, la cantidad de casos correspondiente a cada estrato será 80 (\(0,2\)*\(400\)), 180 (\(0,45\)*\(400\)) y 140 (\(0,35\)*\(400\)).
2.5.2.6.2 Procedimiento de selección de unidades dentro de los estratos
Luego de haber definido los estratos y asignado un tamaño a cada uno de ellos, el paso siguiente es la selección de las unidades dentro de cada uno de ellos. Los métodos de selección pueden ser:
Muestreo Aleatorio Simple (MAS), que asigna idéntica probabilidad de selección a cada elemento del estrato y en donde el azar determina la selección de cada unidad;
Muestreo Sistemático, que también adjudica idéntica probabilidad de selección, pero en donde se sigue un procedimiento sistemático de selección, con arranque aleatorio, ordenando previamente las unidades del universo de acuerdo a una variable relevante (por ejemplo, tamaño).
Recomendación: En virtud de lo expuesto, el muestreo estratificado con asignación proporcional y proceso de selección sistemática se revela como la mejor opción para las encuestas de usos de alojamientos turísticos, allí donde la población alcanza un tamaño destacado. En efecto, los padrones de establecimientos de alojamiento poseen variadas características conocidas (clase, categoría y/o ubicación) que permiten realizar una adecuada estratificación previa a la selección, y así obtener una muestra que refleje la variabilidad de la población de origen. Luego, en cada estrato, es recomendable ordenar a los establecimientos por su tamaño (cantidad de plazas o habitaciones) y extraer en forma sistemática las unidades que compondrán la muestra.
2.5.2.6.3 Otras consideraciones sobre muestreo estratificado
En primer lugar, si bien se recomienda realizar relevamientos sobre muestras (dadas sus ventajas operativas y estadísticas), existen situaciones en donde se hace necesario un relevamiento de tipo censal. Es el caso de los estratos pequeños pero de gran importancia relativa, como ser los hoteles de alta categoría (4 y 5 estrellas), que es un criterio adoptado en la EOH. Este estrato presenta un peso relativo pequeño dentro de la población bajo estudio, pero se supone que tiene un comportamiento diferencial con respecto al resto de los estratos. Por lo tanto, es estos casos se recomienda relevar a todos los establecimientos que forman parte del estrato (censo dentro del estrato), para garantizar una base robusta a partir de la cual realizar estimaciones.
Por otro lado, luego de haber asignado proporcionalmente los casos a cada estrato, puede que en alguno de ellos la cantidad de casos sea muy pequeña. En estos casos, es posible asignar mayor cantidad de casos a ese estrato (sin llegar a realizar un censo), con el fin de alcanzar una base de análisis que garantice estimaciones estadísticamente significativas para ese estrato.
Cabe mencionar que, en este último caso, al momento de construir los ponderadores (véase Ponderadores o factores de expansión), deberá contemplarse devolver a las unidades de dichos estratos el peso que originalmente tenían (es decir, aquel que corresponde a sus probabilidades de selección).
Para finalizar, como puede deducirse, la estratificación, en sí misma, no es un procedimiento de selección de unidades, sino que constituye un proceso previo a la selección de la muestra. Los procedimientos de selección de la muestra son los que ya se han desarrollado: MAS y Muestreo Sistemático.
2.5.2.6.4 Estratos vs dominios de análisis
En este punto, es necesario aclarar que estrato no es sinónimo de sub-dominio de análisis, entendiendo a este último como una nueva base de análisis, aparte de la base total: p.e., hoteles de 4 y 5 estrellas, apart hoteles, etc. Sin embargo, a menudo existe una coincidencia entre estrato y sub-dominio de análisis. Ejemplificando, los hoteles de 3 estrellas junto a los apart hoteles y a los hoteles boutique pueden conformar un mismo estrato y, a la vez, constituir un sub-dominio de análisis. Lo que debe considerarse es que el fin último de la estratificación no es la definición de otras bases de análisis, además de la base total, sino:
reflejar en la muestra la estructura poblacional, en torno a alguna variable que se juzgue relevante para el objetivo de estudio;
reducir la dispersión general de la población en torno a la variable de estudio que se considere más relevante para el estudio;
lograr mayor precisión en los resultados;
reducir el tamaño de muestra.
Finalmente, si uno de los propósitos del estudio fuese analizar los resultados en sub-dominios de la población (p.e. si interesara conocer, además del total provincial de hoteles, los niveles de ocupación para la capital provincial por un lado, y para el resto de la provincia por otro, y dentro de cada uno de ellos, las diferencias entre los hoteles de alta categoría (4 y 5 estrellas) y el resto) es importante tener en consideración que estos sub-dominios deben surgir del agrupamiento de uno o más estratos, y que la cantidad de casos permita realizar estimaciones con un margen de error estadístico aceptable para los objetivos de la investigación).
2.5.2.7 Ejemplo de estratificación y selección de muestras al interior de cada estrato
La provincia X decide realizar un estudio de ocupación hotelera y parahotelera en algunas localidades que componen el territorio provincial. En cada una de las localidades seleccionadas (consideradas como estratos) el relevamiento será muestral. Se desea obtener resultados tanto para el conjunto de localidades como para cada localidad, sin diferenciar, al interior de estas, por tipo o categoría de los establecimientos.
En el ejemplo de la Figura 2.1, se desarrollará el proceso de estratificación y selección de muestras dentro de cada estrato para una sola localidad en particular (localidad Y), que cuenta con el siguiente padrón de establecimientos:
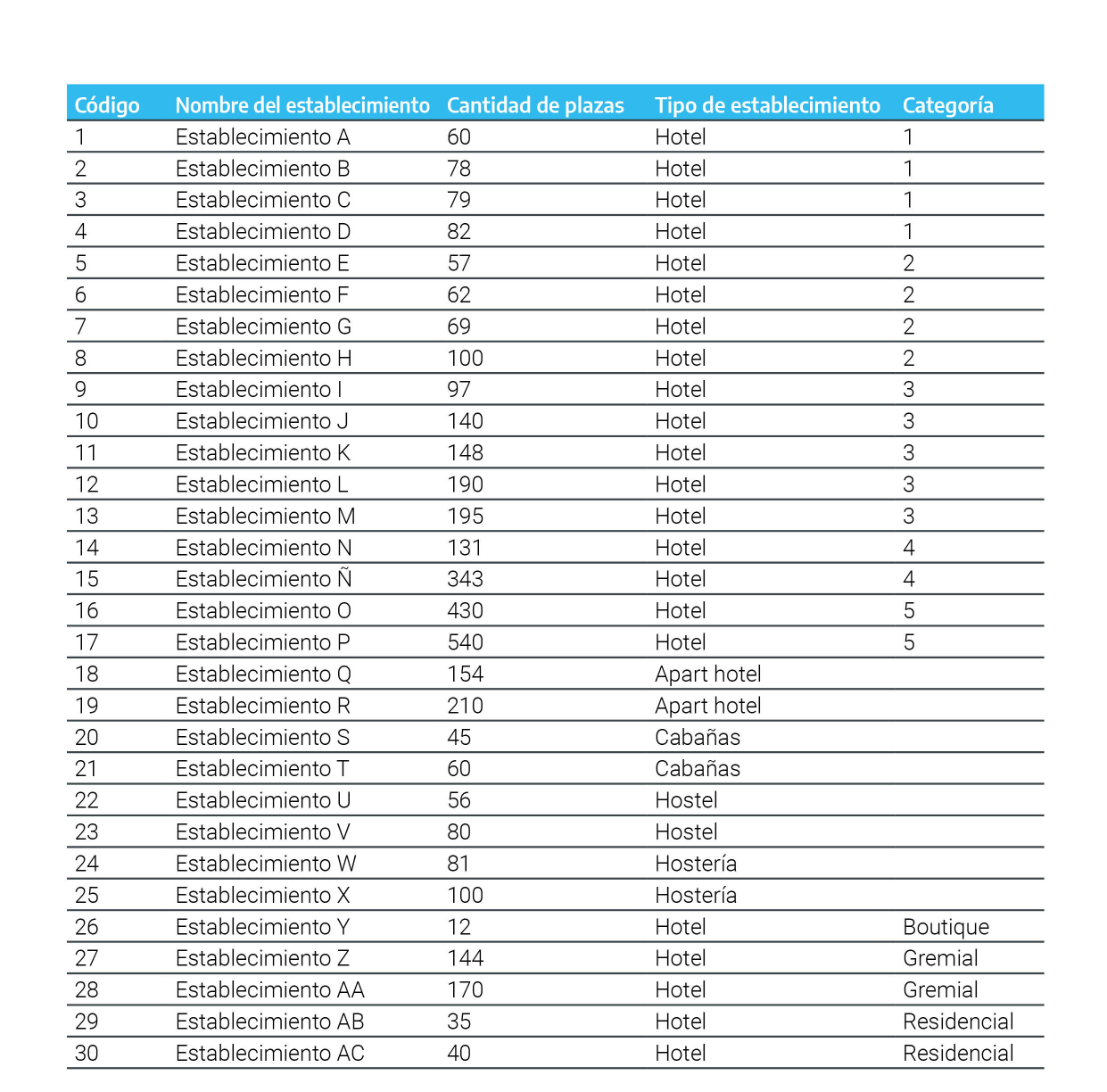
Figura 2.1: Padrón de establecimientos de la localidad Y
2.5.2.7.1 Definición de los estratos en la localidad Y
El primer paso, previo al proceso de selección, consiste en la definición de los estratos. Supóngase que la provincia X tiene conocimiento de que en la localidad en cuestión existe un comportamiento diferencial en cuanto a ocupación según la tipología, categoría del establecimiento y cantidad de plazas disponibles. Por tanto, se decide conformar lo siguientes estratos:
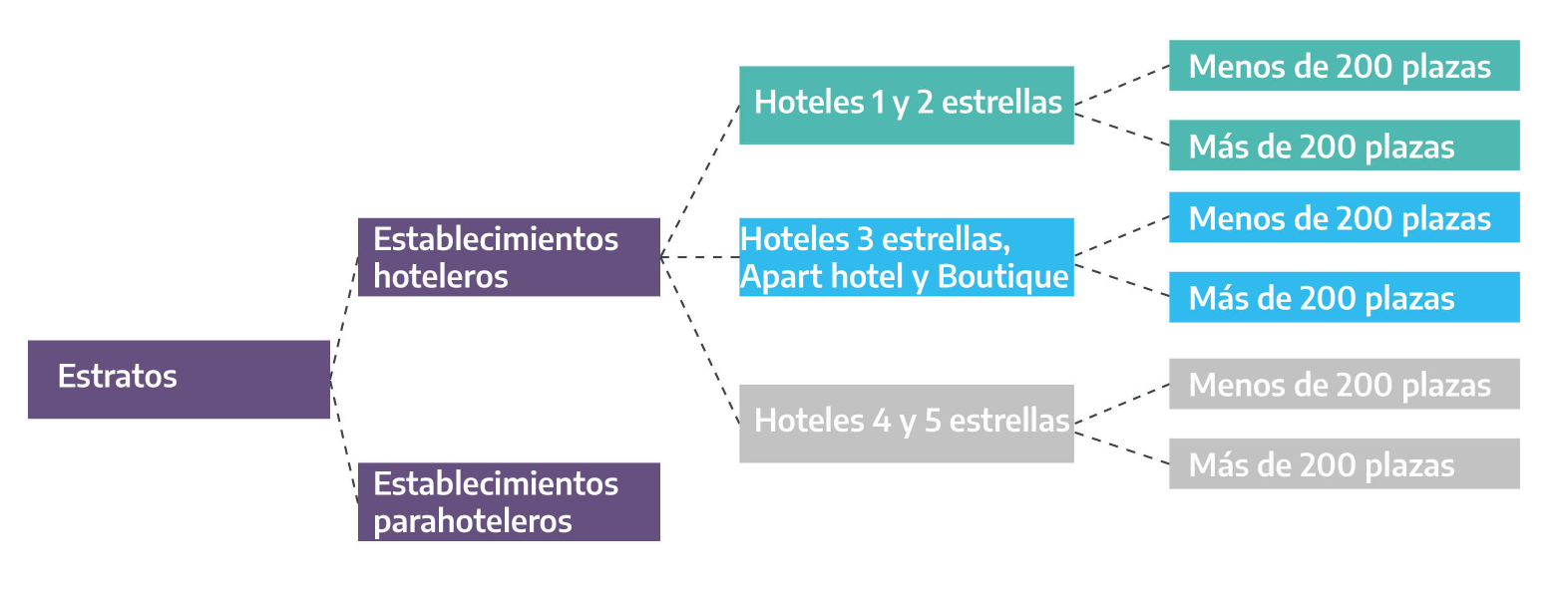
Figura 2.2: Estratos de establecimientos de la localidad Y
Como se puede observar, un primer criterio de estratificación distingue a los establecimientos hoteleros y parahoteleros. Adicionalmente, un segundo criterio de estratificación segmenta a los establecimientos hoteleros en “Hoteles 1 y 2 estrellas” , “Hoteles 3 estrellas, Apart hotel y Boutique” y “Hoteles 4 y 5 estrellas” . Por último, un tercer criterio los diferencia entre si tienen menos o más de 200 plazas, ya que se supone que los establecimientos relativamente grandes (en función de la cantidad de plazas) manifiestan un comportamiento diferencial en relación a los de menor número de plazas. Nótese que el corte en menos o más de 200 plazas es totalmente arbitrario en este ejemplo; en la práctica de cada provincia, el criterio dependerá de las particularidades que manifieste el sector y, obviamente, de los objetivos del estudio.
Una vez definidos los estratos, se procede a clasificar los establecimientos del padrón en estos diferentes sub-universos.
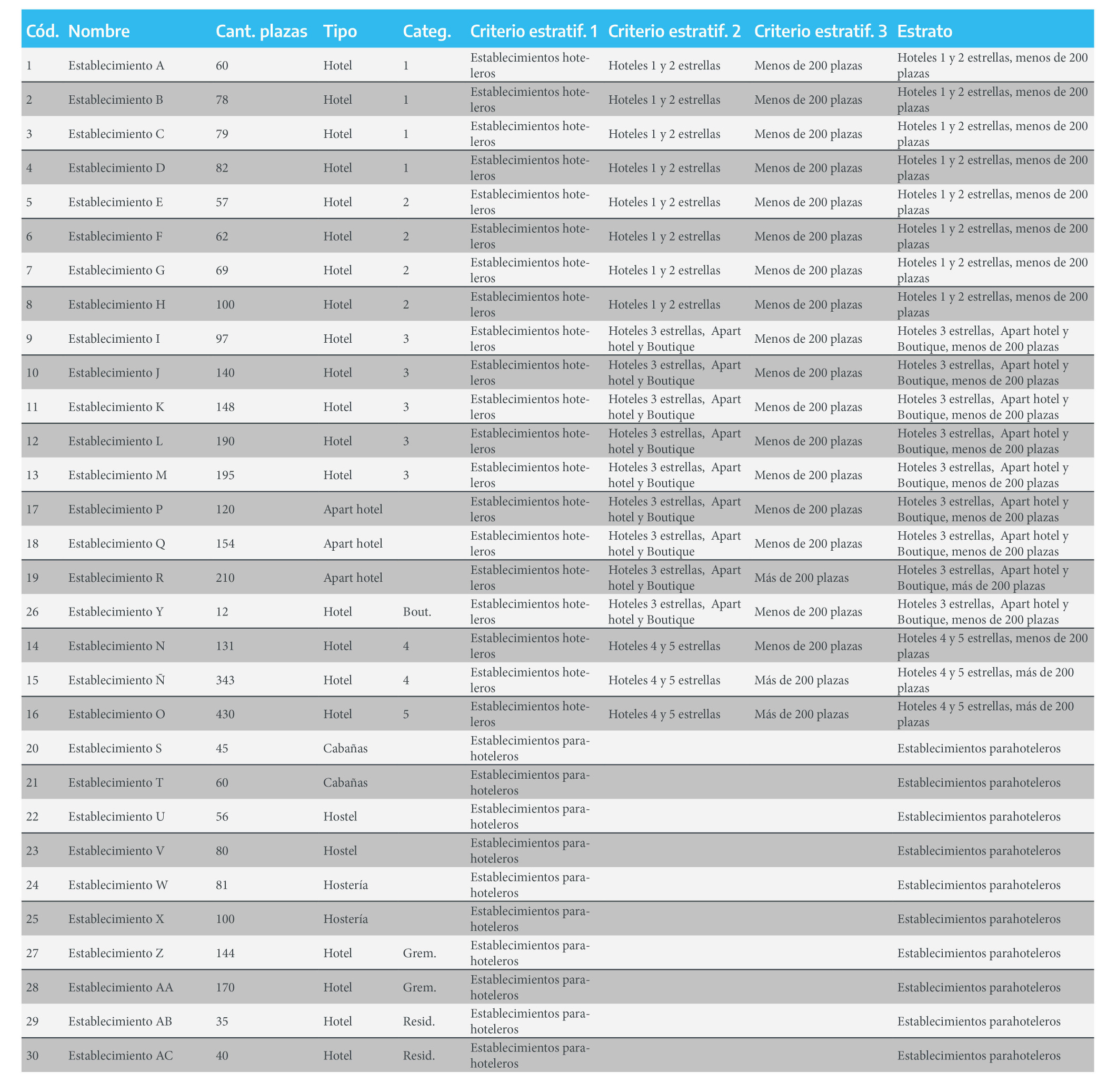
Figura 2.3: Criterios de estratificación y definición de los estratos
2.5.2.7.2 Determinación del tamaño muestral de cada estrato
Como se mencionó en párrafos anteriores, para determinar el tamaño de muestra de cada estrato, es preciso que previamente se haya determinado el tamaño de muestra total para la localidad (es decir, considerando a todos los estratos). En este ejemplo no se desarrollará el proceso de cálculo del tamaño total, sino que se asumirá como dato existente. En este caso, se considerará un tamaño de muestra total de 15 casos12.
En primer lugar, se decide que los hoteles de 4 y 5 estrellas deben tener inclusión forzosa dentro de la muestra total, es decir se relevarán todos los establecimientos de estas categorías independientemente de su cantidad de plazas, debido al bajo peso relativo que presentan en el total de establecimientos y al comportamiento diferencial que tiene este segmento respecto al resto del universo. Por tanto, al total de 15 establecimientos de la muestra final se le deberán restar los 3 establecimientos que forman parte de los estratos “Hoteles 4 y 5 estrellas, menos de 200 plazas” y “Hoteles 4 y 5 estrellas, más de 200 plazas” , quedando un total de 12 establecimientos que deben ser distribuidos entre los restantes estratos.
Por otro lado, siguiendo el mismo razonamiento que en el caso previo, también se toma la decisión de que los establecimientos de 200 o más plazas deben tener inclusión forzosa en la muestra total. Por tanto, el establecimiento R, que dispone de 210 plazas, deberá necesariamente formar parte de la muestra. Los establecimientos Ñ y O ya fueron incluidos forzosamente por tener categoría 4 y 5 estrellas, respectivamente, por lo cual no es necesario repetir el proceso de selección. En esta instancia, quedan 11 establecimientos a ser repartidos entre los diferentes estratos.
El siguiente paso consiste en calcular el tamaño de las muestras de los siguientes estratos:
Hoteles 1 y 2 estrellas, menos de 200 plazas.
Hoteles 3 estrellas, Apart hotel y Boutique, menos de 200 plazas.
Establecimientos parahoteleros.
El equipo técnico de la provincia X tomó la decisión de que la asignación de casos por estrato se ajuste al peso que cada uno tiene sobre el universo total de establecimientos, obviamente restando los alojamientos de 4 y 5 estrellas y el establecimiento de 210 plazas, perteneciente este último al estrato “Hoteles 3 estrellas, Apart hotel y Boutique, más de 200 plazas” . El peso de cada estrato se definirá en función de la cantidad de plazas disponibles del mismo, ya que ésta será una de las principales variables de análisis13. En el siguiente cuadro se realiza el cálculo del peso de cada estrato sobre el total de plazas, luego de haber sustraído las plazas correspondientes a los establecimientos previamente mencionados.
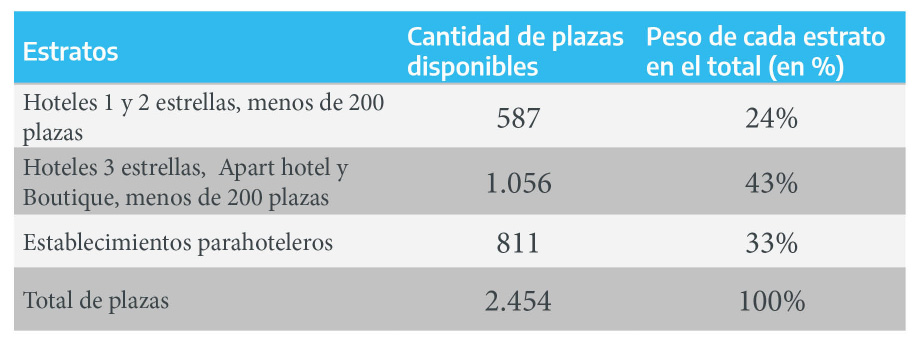
Figura 2.4: Cantidad de plazas
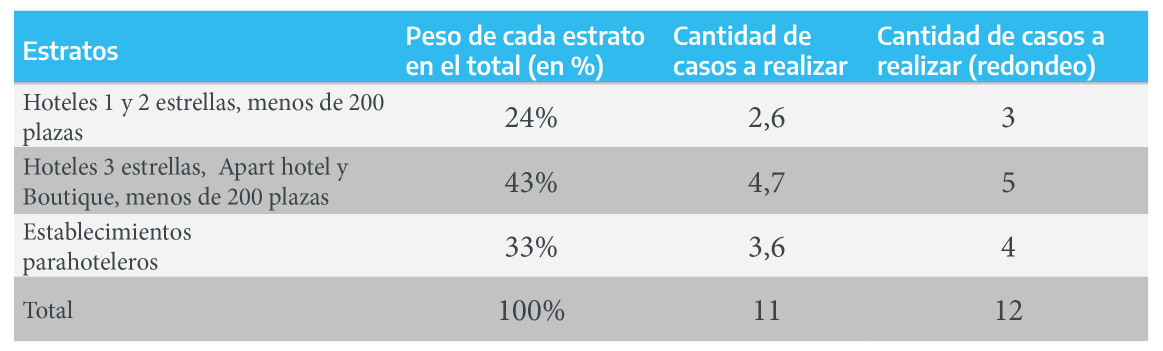
Figura 2.5: Peso de estrato
Los cálculos arrojan que habría que relevar 3 establecimientos del estrato “Hoteles 1 y 2 estrellas, menos de 200 plazas” , 5 del estrato “Hoteles 3 estrellas, Apart hotel y Boutique, menos de 200 plazas y 4 del estrato”Establecimientos parahoteleros" , dando un total de 12 casos. Cabe mencionar que los redondeos suelen dar como resultado un leve aumento del tamaño de muestra originalmente planteado.
La muestra final de establecimientos quedaría distribuida de la siguiente forma:
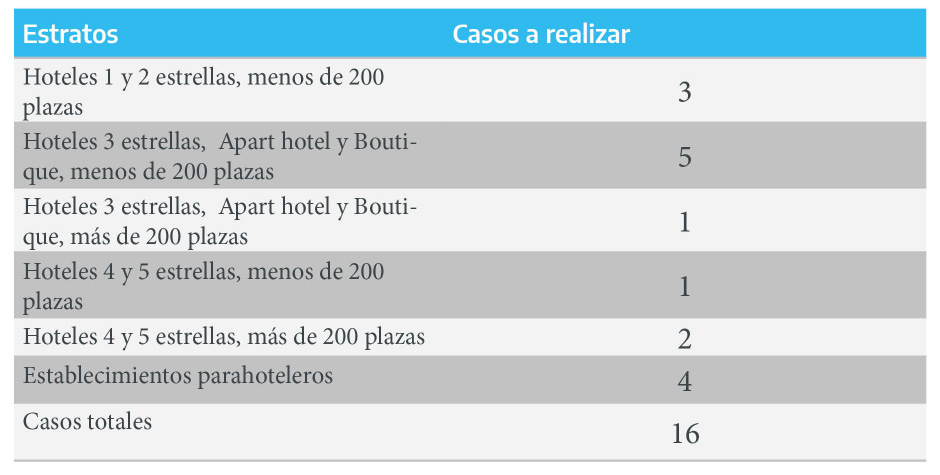
Figura 2.6: Casos a realizar
Una vez que determinados los tamaños de muestra de cada estrato, se procede con la selección de los casos.
2.5.2.7.3 Selección de los casos al interior de cada estrato
Dentro de cada estrato, se ordenan los casos en función de la variable plazas disponibles, ya que se supone que tiene correlación con el comportamiento de las variables bajo estudio, siguiendo algún sentido (de menor a mayor, o viceversa). En este caso, se ordena de menor a mayor.
Luego se enumeran los establecimientos dentro de cada estrato.
Seguidamente se calcula el “intervalo de selección” , que es el resultado de dividir la cantidad de establecimientos total del estrato (Nf) por el tamaño de la muestra en el mismo (nf). Como ya se mencionó previamente, el intervalo de selección define la cantidad de establecimientos que debe haber entre una y otra selección. De este modo, el intervalo de selección en cada estrato será:
Hoteles 1 y 2 estrellas, menos de 200 plazas: \(8/3\)=\(2,7\)=\(3\).
Hoteles 3 estrellas, Apart hotel y Boutique, menos de 200 plazas: \(8/5\)=\(1,6\)=\(2\).
Establecimientos parahoteleros: \(10/4\)=\(2,5\)=\(3\).
El paso siguiente es, dentro de cada estrato, elegir aleatoriamente un número (r) entre 1 y el resultado de N/n. Este número definirá la posición del establecimiento a partir del cual comienza la selección sistemática (arranque aleatorio). Supóngase que los números aleatorios obtenidos para cada estrato son:
Hoteles 1 y 2 estrellas, menos de 200 plazas: \(r=2\).
Hoteles 3 estrellas, Apart hotel y Boutique, menos de 200 plazas: \(r=2\).
Establecimientos parahoteleros: \(r=1\).
En esta instancia se está en condiciones de realizar la selección sistemática de los establecimientos a ser relevados, tal como se muestra a continuación.
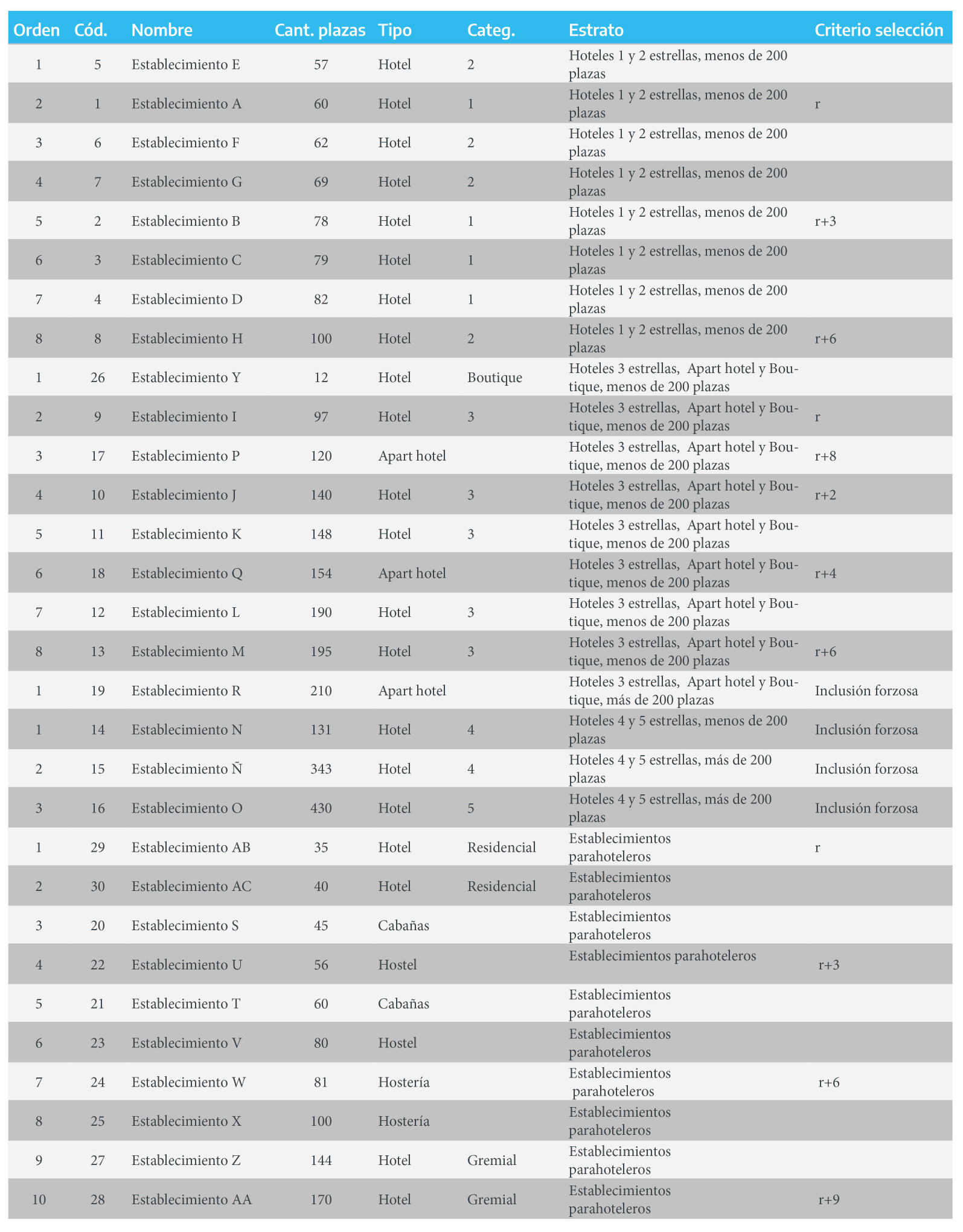
Figura 2.7: Selección de las muestras al interior de cada estrato
Nótese que, en cada estrato, el primer elemento seleccionado es el definido por el arranque aleatorio (r). Luego, el segundo elemento estará definido por \(r\)+(\(N/n\)=intervalo de selección). Por ejemplo, en el estrato “Hoteles 1 y 2 estrellas, menos de 200 plazas” , el segundo elemento será el que está ubicado en la posición 5, ya que \(2+3\)=\(5\); y el tercer elemento será \(2+6\)=\(8\).
En el estrato “Hoteles 3 estrellas, Apart hotel y Boutique, menos de 200 plazas” , el último establecimiento seleccionado es el que se encuentra en la posición 3, ya que el inmediatamente anterior fue el 8, y luego de esta posición ya no había más establecimientos, por lo cual fue necesario realizar la selección desde el principio.
Finalmente, los establecimientos que componen la muestra son:
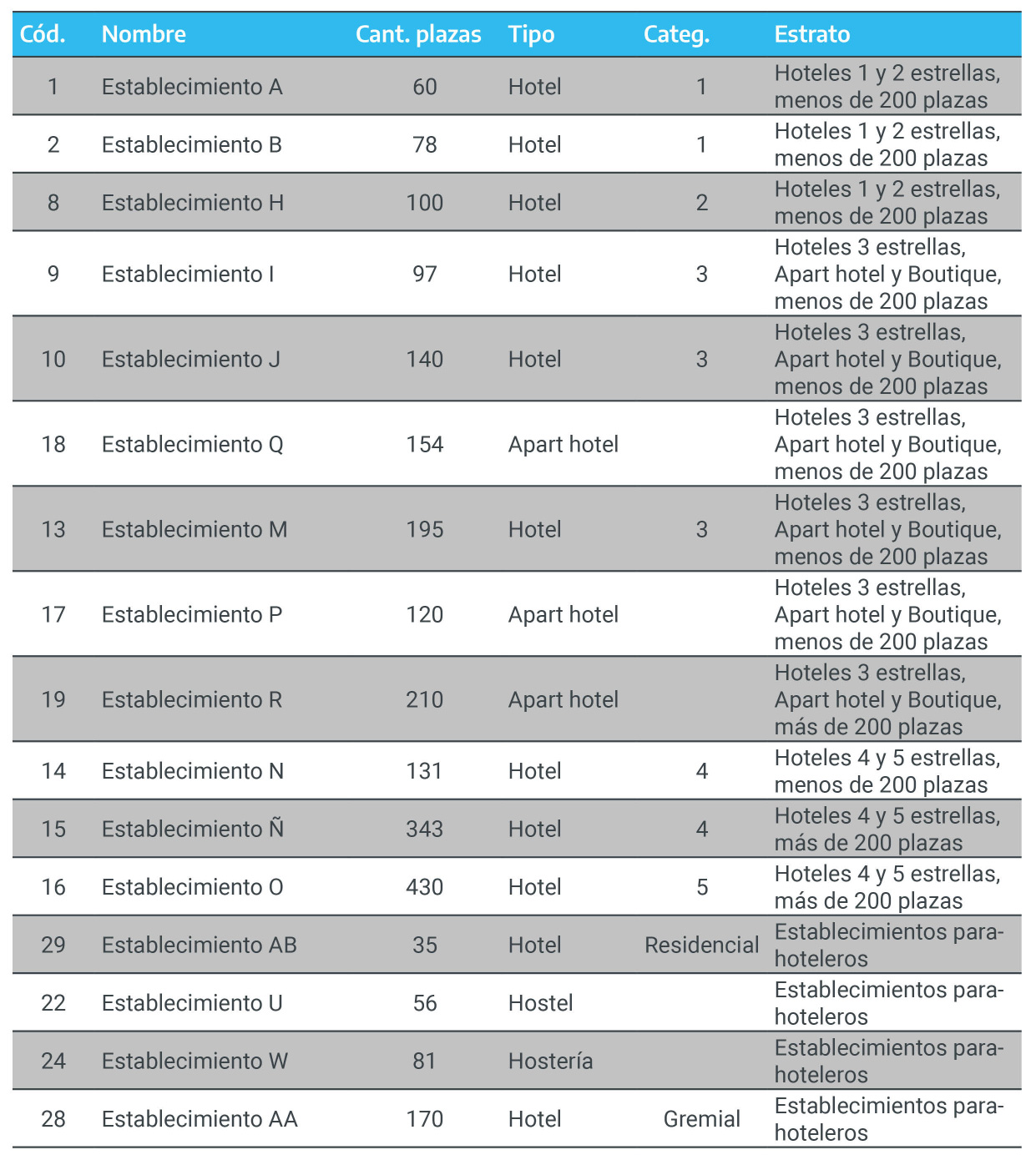
Figura 2.8: Muestra final de establecimientos
Por último, recuérdese que los criterios elegidos en este ejemplo para la estratificación son hipotéticos. Por tanto, en cada provincia y/o municipio, los criterios a partir de los cuales se estratificará al universo de establecimientos dependerán de la realidad propia del sector así como a los objetivos de estudio.
2.5.3 Construcción del formulario de registro (cuestionario o planilla): definición de variables fundamentales
Un aspecto central en el diseño de una investigación es la definición de las variables, que son las características o atributos que interesan ser observados o medidos en la población bajo estudio. Por ejemplo, en el caso específico de los relevamientos de alojamientos turísticos, las variables específicas a medir pueden ser “cantidad de plazas ocupadas” , “cantidad de plazas disponibles” , “cantidad de habitaciones ocupadas” , “cantidad de habitaciones disponibles” , “nuevos viajeros alojados” , “tarifa media” , etc. Lógicamente, las variables se desprenden de los objetivos de investigación. Por lo tanto, cuánto más claros sean los objetivos, mayor será la probabilidad de plantear variables relevantes que permitan alcanzarlos.
En las investigaciones de carácter socio-económico, dentro de las cuales se incluyen los relevamientos de alojamientos turísticos, la información referida a las variables de estudio es recolectada por medio de preguntas, que suelen estar dispuestas en cuestionarios. El cuestionario es, por lo tanto, el instrumento de recolección de información sobre variables que buscan caracterizar a una población14.
Las variables pueden ser medidas de forma directa o indirecta. Las variables de medición directa son aquellas que pueden ser obtenidas mediante una sola pregunta. Por ejemplo, el valor de la variable plazas ocupadas se obtiene mediante la pregunta: ¿cuál es la cantidad de plazas ocupadas? Por otro lado, existen variables que presentan un mayor grado de abstracción o complejidad, y que requieren de más de una pregunta para ser medidas. Este es el caso de, por ejemplo, la tasa o porcentaje de ocupación en plazas, que se obtiene mediante el cociente entre cantidad de plazas ocupadas y cantidad de plazas disponibles (es decir, dos variables distintas).
Para finalizar, en este documento se asimilará el concepto de variable con el de indicador, a pesar de que ambos puedan presentar diferencias sutiles. En este sentido, plazas ocupadas y tasa de ocupación en plazas, así como otras variables referidas a alojamientos turísticos, constituyen indicadores.
2.5.3.1 Variables e indicadores en una encuesta de alojamientos turísticos
En este sub-apartado se presentarán las diferentes variables que pueden ser relevadas a través de una encuesta de alojamientos turísticos. En primer lugar se enumeran y describen aquellas variables cruciales para la estimación de indicadores básicos, tales como porcentaje de ocupación en plazas y/o habitaciones, o pernoctaciones.
Por tanto, las variables elementales que pueden ser relevadas en este tipo de operativos son:
plazas ocupadas;
plazas disponibles;
habitaciones o unidades ocupadas15;
habitaciones o unidades disponibles;
cantidad de nuevos viajeros alojados (o cantidad de viajeros ingresados);
(eventualmente) lugar de residencia de los viajeros alojados.
La variable “plazas ocupadas” resulta crucial, dado que constituye uno de los insumos elementales para la estimación del “porcentaje de ocupación en plazas” (plazas ocupadas / plazas disponibles, en un período determinado) y de las “pernoctaciones” (suma de las plazas ocupadas de todos los establecimientos en un período determinado). En el caso del porcentaje de ocupación en plazas, como se observa, la variable plazas ocupadas interviene en el numerador de la fórmula de cálculo.
Es recomendable que, la cantidad de plazas ocupadas sea relevada en términos absolutos (es decir, como cantidad). El mismo criterio aplica para la cantidad de habitaciones ocupadas, variable que participa en la estimación del porcentaje de ocupación en habitaciones (cuya fórmula es cantidad de habitaciones ocupadas/ cantidad de habitaciones disponibles).
En este sentido, muchas jurisdicciones suelen preguntar directamente por el porcentaje de ocupación correspondiente en ese lugar durante un periodo dado. Luego, multiplican ese porcentaje por la cantidad de plazas o habitaciones disponibles (según corresponda), obteniendo de ese modo los valores absolutos. Esta forma de cálculo encierra muy probablemente un tipo de error no estadístico, que es de una magnitud mayor a cuando se pregunta por cantidades y, complicando aún más la situación, esa cuantía no puede ser estimada. El error está en suponer que el informante responderá en forma precisa por la tasa de ocupación, cuando es posible que su subjetividad lo sesgue a declarar un valor “promedio” (perdiendo sentido la serie histórica que el estudio procura construir) o bien de algún sub-período del periodo de referencia (un fin de semana, en lugar de toda la semana por ejemplo). Asimismo, el entrevistado también puede confundir el porcentaje de ocupación en plazas con el porcentaje de ocupación en habitaciones. Cuánto más concreta y objetiva sea la pregunta, mayor será la calidad de la información obtenida.
Adicionalmente, es conveniente también indagar siempre por la cantidad de "plazas disponibles" y “habitaciones disponibles”, variables que formarán parte del denominador en las estimaciones de “porcentaje de ocupación en plazas” y “porcentaje de ocupación en habitaciones”, respectivamente. Si bien la información referida a disponibilidad en plazas y habitaciones puede estar presente en el padrón de establecimientos de alojamiento turístico, la medición de estas variables en el relevamiento podría ser útil, con el doble propósito de:
contar con información actualizada al momento de realizar las estimaciones: las plazas y habitaciones disponibles del período analizado puede diferir respecto a la del padrón, debido a cierres temporarios o definitivos de establecimientos, o clausura temporaria o definitiva de habitaciones (con la consecuente reducción de plazas);
corregir posibles inconsistencias o actualizar la información del padrón de alojamientos (cuando corresponda);
La variable “cantidad de nuevos viajeros alojados (o cantidad de viajeros ingresados)” también resulta útil para realizar una aproximación a la estimación de la cantidad de turistas en el destino. Si se decide medirla, es preciso que se clarifique que lo correcto es registrar la cantidad de nuevos viajeros en el período de referencia, y no la cantidad de total viajeros alojados. En efecto, en este último caso, se estaría contando más de una vez al mismo viajero. Si por algún motivo no se pudiese incluir esta pregunta, es posible realizar una estimación de la cantidad de viajeros dividiendo pernoctaciones en determinado período por “estadía promedio” . La información sobre estadía promedio es conveniente obtenerla de otra fuente de información (por ejemplo, encuestas de demanda o perfil del turista), dado que al indagar directamente por la estadía promedio se correría el riesgo de caer en posibles errores de cálculo por parte del respondente (además de mediar su subjetividad).
En caso de incorporarse a la medición la variable “lugar de residencia habitual” , debajo se propone una clasificación posible, con un nivel de desagregación de máxima, que cada jurisdicción acotará (o no) atendiendo a los objetivos propios de investigación y a la duración del cuestionario.
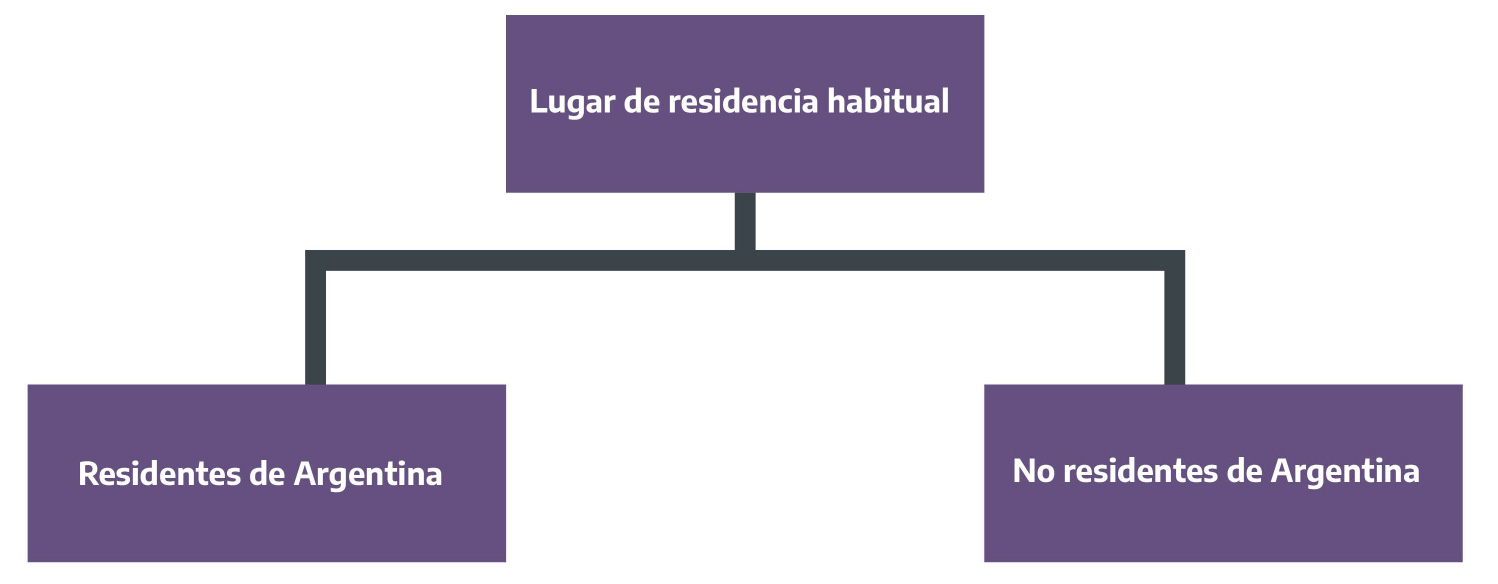
Figura 2.9: Lugar de residencia habitual
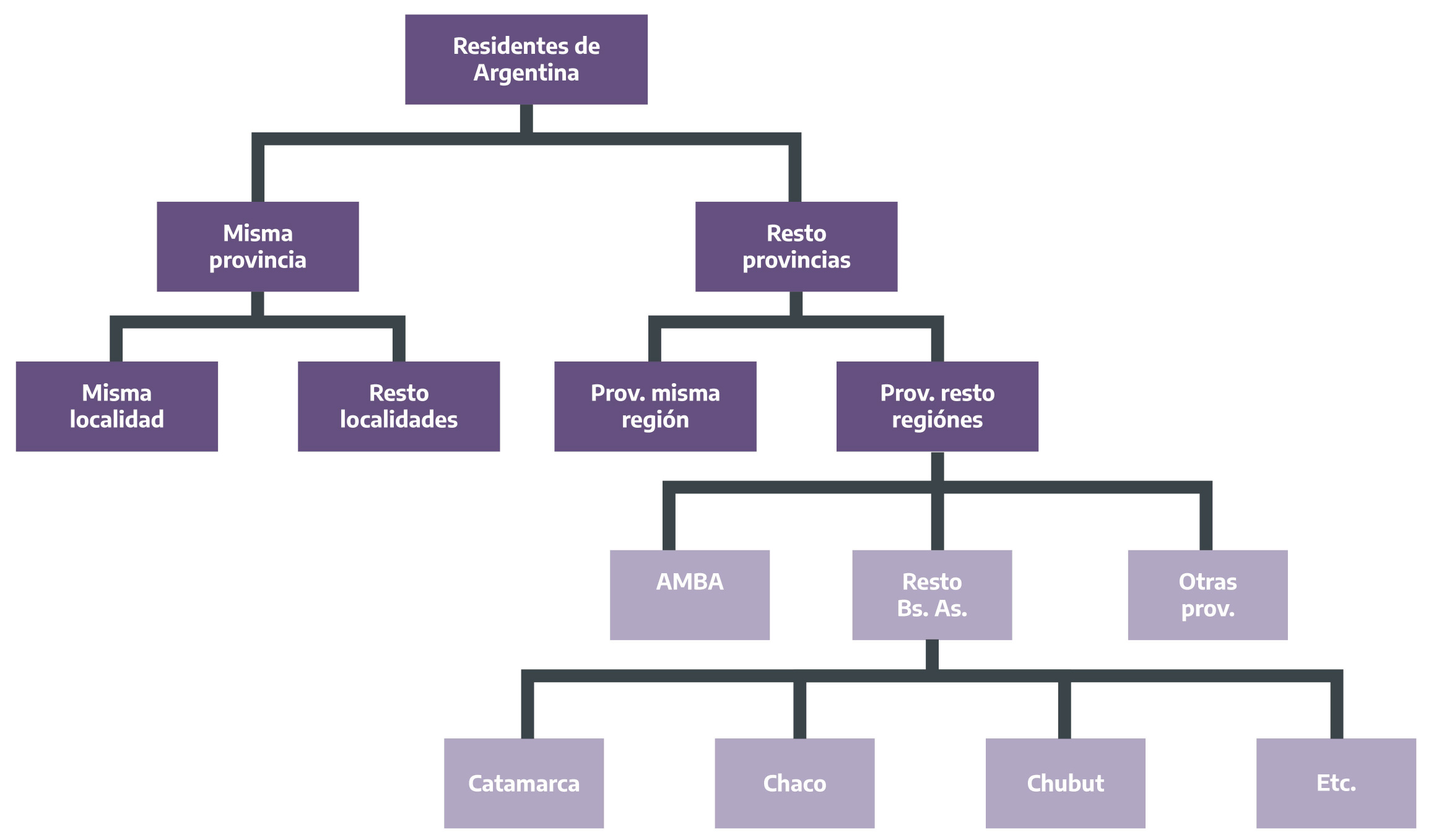
Figura 2.10: Lugar de residencia habitual. Residentes de Argentina
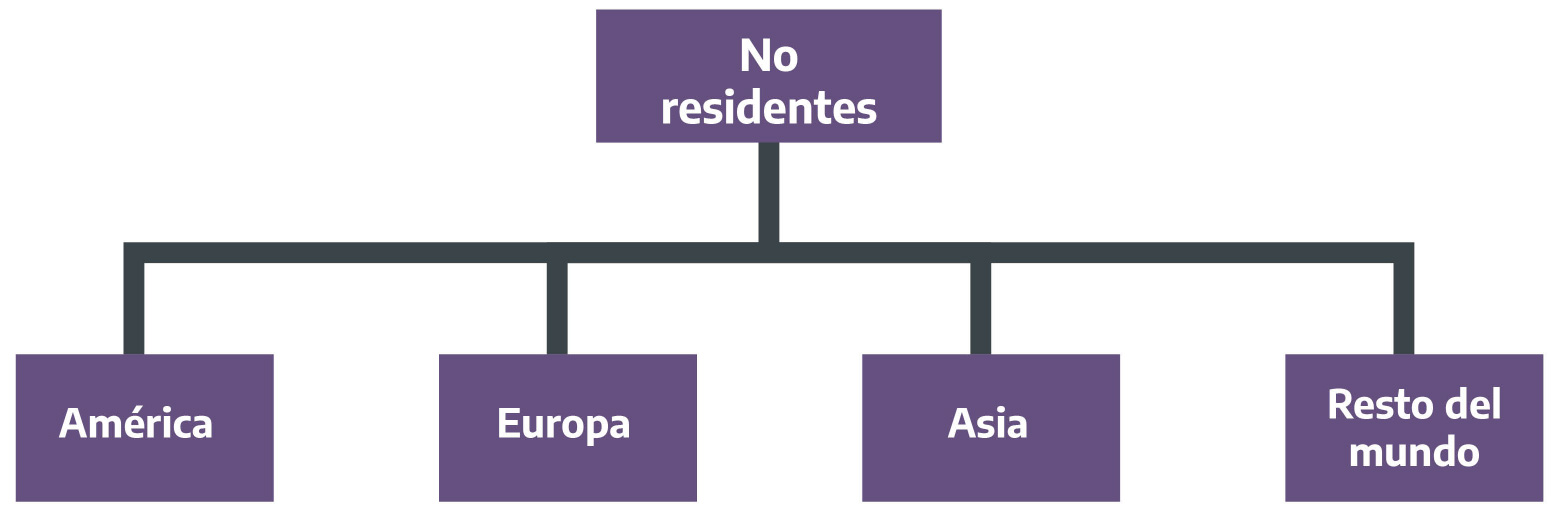
Figura 2.11: Lugar de residencia habitual. No residentes de Argentina
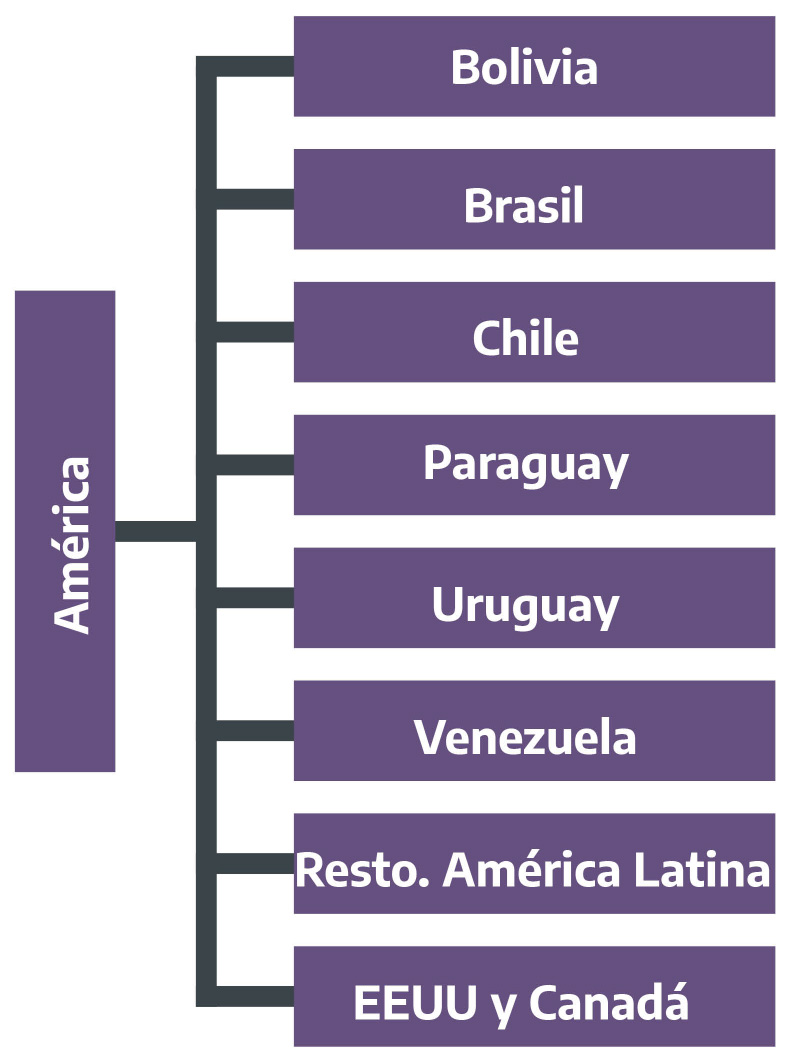
Figura 2.12: Lugar de residencia habitual. No residentes de Argentina. América
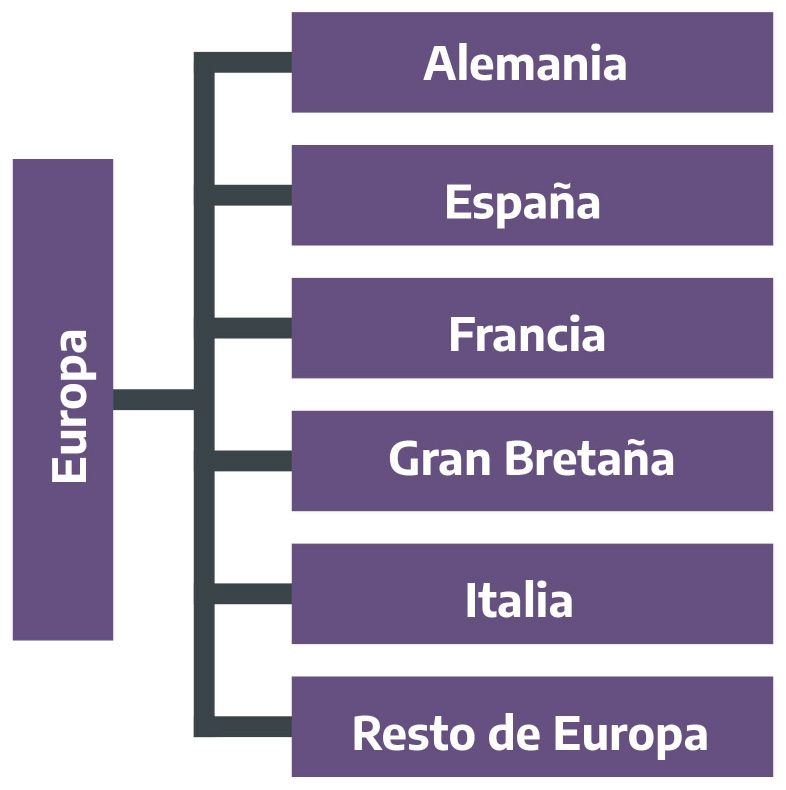
Figura 2.13: Lugar de residencia habitual. No residentes de Argentina. Europa
La medición de las variables mencionadas previamente resulta de gran importancia, dado que permiten estimar los diferentes indicadores que son objeto de estudio en las distintas provincias, departamentos y municipios del país. Sin embargo, si fuese necesario aplicar un cuestionario de menor duración, sería posible reducir la cantidad de variables a relevar. En cualquier caso, la variable fundamental, que no debería faltar en ningún relevamiento de alojamientos turísticos es “plazas ocupadas” , dado que, como ya se indicó, permite la estimación de otros indicadores fundamentales: porcentaje de ocupación en plazas y pernoctaciones. Luego de garantizar la inclusión de esta variable en el cuestionario (o planilla de registro), el orden recomendado de inclusión de otras variables sería “plazas disponibles” , “habitaciones ocupadas” , “habitaciones disponibles” y “cantidad de nuevos viajeros alojados (o cantidad de viajeros ingresados)” .
Como se desprende de lo desarrollado previamente, en caso de no incluir en el cuestionario a las variables “plazas disponibles” y “habitaciones disponibles” , la información sobre las mismas puede ser obtenida de los padrones de establecimientos de alojamiento turístico, tomando los recaudos necesarios en cuanto a su actualización.
Para finalizar, existen otras variables que pueden ser relevadas mediante un operativo de alojamientos:
- En relación al empleo, puede indagarse la cantidad de personas ocupadas en el establecimiento. Más aún, a las personas ocupadas se las podría clasificar tal como se sugiere debajo:

Figura 2.14: Categorías ocupacionales utilizadas en la EOH (MINTURDEP-INDEC)
Tarifas en el período de referencia: las tarifas pueden ser medidas siguiendo diferentes criterios. Por ejemplo, pueden relevarse las tarifas de todos los tipos (single, doble, triple, cuádruple) y categorías (estándar, superior, etc.) de habitaciones del establecimiento. También puede indagarse la tarifa promedio del tipo de habitación con mayor cantidad de unidades disponibles en el establecimiento. Otra alternativa podría ser recabar la tarifa del tipo de habitación con mayor nivel de demanda. De forma similar a la anterior variable, cada jurisdicción podrá optar por el criterio de medición más adecuado a sus objetivos de estudio y características del relevamiento.
2.6 Clasificación de los establecimientos de alojamiento turístico
Sin perder de vista las particularidades provinciales/departamentales/municipales que encierra la definición de cada clase de establecimiento, producto de las normativas vigentes en cada jurisdicción, en este apartado se planteará una propuesta mínima de clasificación de los mismos. La misma es empleada en los padrones del MINTURDEP y puede ser útil para establecer equivalencias entre las diferentes definiciones adoptadas en cada jurisdicción.
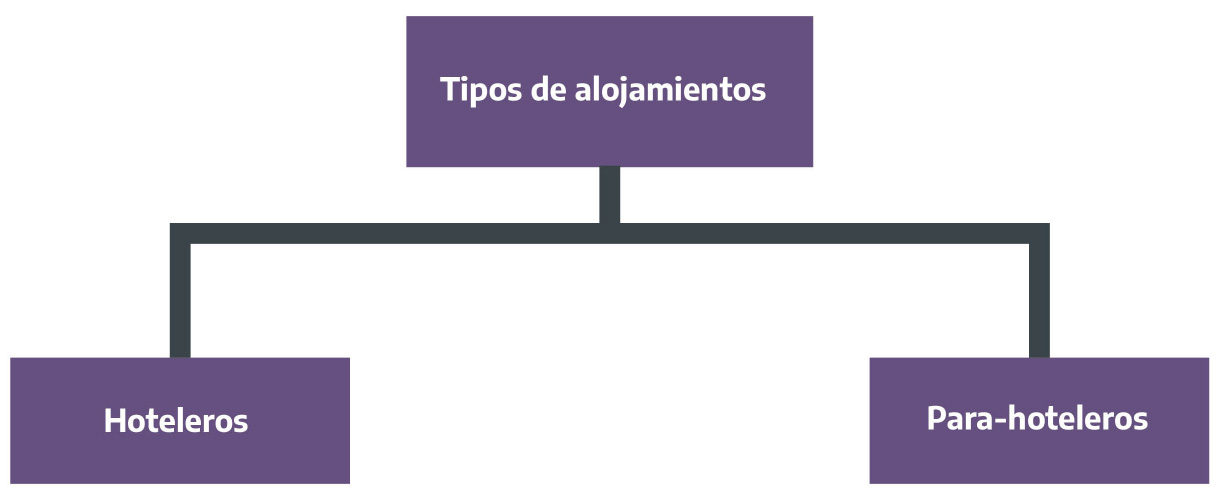
Figura 2.15: Tipos de alojamientos turísticos
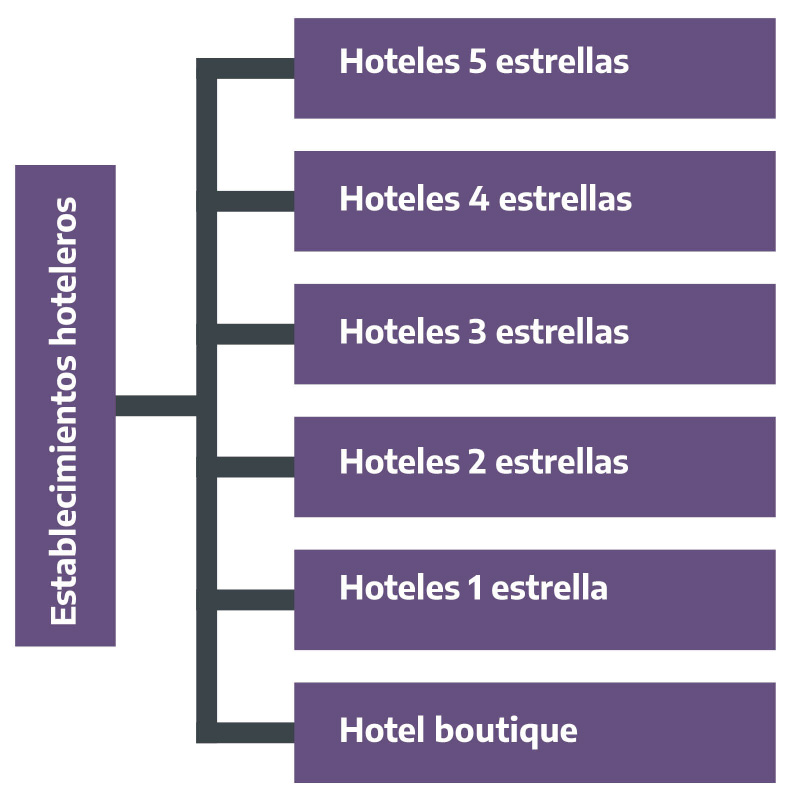
Figura 2.16: Tipos de alojamientos turísticos. Establecimientos hoteleros
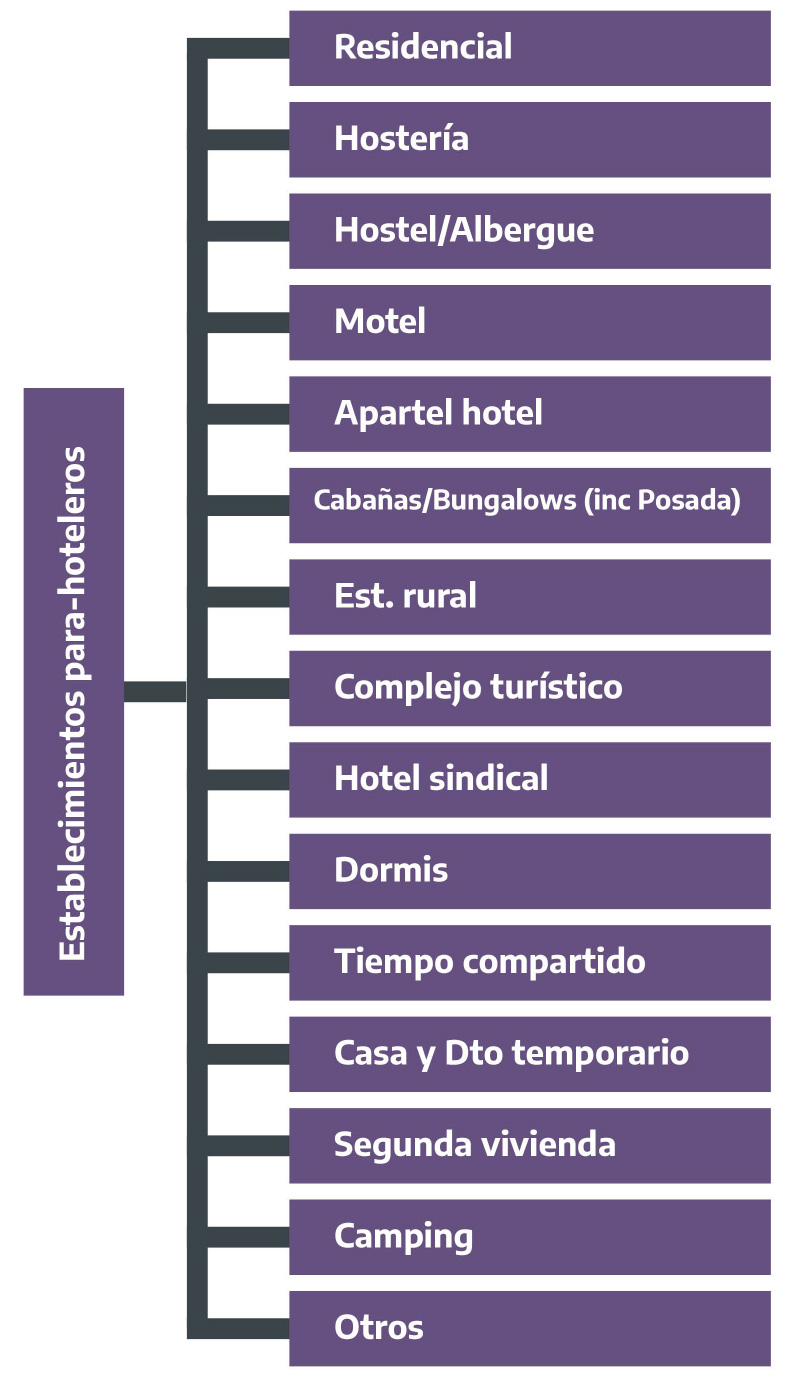
Figura 2.17: Tipos de alojamientos turísticos. Establecimientos para-hoteleros
2.7 Trabajo de campo
2.7.1 Frecuencia de relevamiento y período de referencia de los datos relevados
El trabajo de campo (el momento del relevamiento de la información en sí), de forma similar a las otras etapas del estudio, también debe ser planificado de antemano, si bien en el transcurso del estudio pueden ir planteándose modificaciones.
Un punto importante es determinar la periodicidad con la que la información será recolectada, es decir, la frecuencia con la que se hará la toma del dato. Por ejemplo, dentro de un relevamiento continuo, es necesario definir si la recolección de los datos será mensual, quincenal, semanal, durante algunos días específicos de la semana o diaria. Lo mismo vale para un relevamiento puntual. Por ejemplo, en un operativo de temporada alta, es preciso determinar si los datos serán recolectados quincenalmente, semanalmente, durante algunos días específicos de la semana o diariamente.
Otro aspecto que merece ser definido con claridad es el período de referencia de los datos a relevarse. En otras palabras, debe establecerse a qué período estarán referidas las variables por las que se indagará. Este punto está fuertemente ligado a la frecuencia con la que se realice el relevamiento. En efecto:
En los relevamientos diarios, el período de referencia de los datos relevados será el día anterior: por ejemplo, el martes se preguntará por la cantidad de plazas ocupadas del lunes; el miércoles por las del martes; el lunes por las del sábado y domingo (en este caso, se indagará por los dos días ya que los fines de semana no suelen ser días laborales).
En los relevamientos con frecuencia semanal, es preciso definir si se preguntará, por ejemplo, por las plazas ocupadas de cada día de la semana o de toda la semana. En este último caso, como la estimación de las plazas totales del período será tarea del respondente, deberían tomarse los recaudos necesarios para reducir al máximo las probabilidades de error de cálculo.
En los estudios con tomas de datos mensuales, las alternativas podrían ser solicitar datos por cada día del mes (situación más viable en relevamientos con entrevistas personales o con formularios autoadministrados) o por el período completo (todo el mes), lo cual conlleva a tomar los mismos recaudos que en los relevamientos semanales con datos referidos a toda la semana (por lo cual resulta la opción menos recomendable).
Por último, en los operativos que relevan datos más de una vez por semana, pero no todos los días, por ejemplo, los lunes y miércoles, es necesario establecer si se recabará información de todos los días previos a los días de relevamiento (lunes y martes) o de algún día específico del período previo, que se considere parecido al resto de los días no relevados.
La última alternativa citada resulta recomendable en relevamientos telefónicos que buscan reducir la frecuencia y duración de los llamados. Sin embargo, en caso de optar por ella, es preciso tener en cuenta que la definición de los días en que se realizará el relevamiento, así como también del día de referencia del dato relevado, no es un procedimiento automático. Por el contrario, supone un análisis y evaluación de las diferencias que podrían presentar las variables bajo estudio entre los diferentes días de la semana.
Cabe mencionar que, como se recabarán datos de dos o tres días de la semana, que luego deberán ser extrapolados al resto de los días, es imprescindible que los días sobre los que se relevarán datos (días de referencia) sean representativos de los días no relevados. Esto implica que los días de referencia deberán ser lo más parecidos posible a los días no relevados en función de las variables bajo análisis. Por tanto, un primer paso es la definición de los días de referencia. Para ello, es preciso analizar el comportamiento de las semanas y conformar grupos de días. Los días de cada grupo deberían ser lo más parecidos entre sí en función de las variables que serán medidas en el estudio; asimismo, cada grupo debe intentar diferenciarse lo más posible de los otros. En definitiva, se estarían definiendo estratos compuestos por días de la semana. A modo de ejemplo, podría suponerse, luego analizar datos provenientes de estudios previos, que los días domingo, lunes, martes, miércoles y jueves suelen manifestar un menor porcentaje de ocupación, así como una menor cantidad de ingresos de viajeros, que los días viernes y sábado. Por tanto, se conformarían dos grupos:
Grupo A: días domingo, lunes, martes, miércoles y jueves.
Grupo B: días viernes y sábado.
Una vez establecidos los grupos de días, es necesario definir qué día de cada grupo se constituirá en día de referencia. Recuérdese que éste será el día sobre el cual se relevarán los datos, que luego serán extrapolados al resto de los días del grupo. La decisión de cuál será el día de referencia dependerá, en gran medida, del día en que pueda realizarse efectivamente el relevamiento y del funcionamiento operativo del equipo de estadísticas de la entidad de turismo. Supóngase que, por razones obvias, el equipo a cargo de las estadísticas de turismo no trabaje el fin de semana. Por tanto, los datos de cualquiera de los días del grupo B deberán ser relevados durante la semana. Lo más lógico es hacerlo un día cercano al día de referencia; por tanto, podría definirse al lunes como día en el que se relevarán los datos del sábado (día que será representativo de sí mismo y del viernes). En cuanto al grupo A, si ya se ha designado al lunes como día de relevamiento de información sobre el sábado, podría decidirse que el día de relevamiento del grupo A esté algo alejado del correspondiente al grupo B. Consecuentemente, los días miércoles o jueves podrían ser buenos candidatos a días de relevamiento del grupo A. Si, por ejemplo, se decidiese que el miércoles sea el elegido, lo más adecuado sería que el día de referencia sea el martes. En síntesis, en este caso hipotético, la conformación de los grupos sería la siguiente:
- Grupo A:
Día de relevamiento: miércoles.
Día de referencia: martes.
Días a los que se extrapolarán datos del martes: domingo, lunes, miércoles y jueves.
- Grupo B:
Día de relevamiento: lunes.
Día de referencia: sábado.
Días a los que se extrapolarán datos del sábado: viernes.
Ahora bien, una vez relevados los datos de los días martes y sábados, ¿cómo se extrapolan (o expanden) los datos al resto de los días? Supóngase que una de las variables relevadas es plazas ocupadas, y que en la semana X se obtienen los siguientes datos:
Martes: 450 plazas ocupadas.
Sábado: 900 plazas ocupadas.
Si se expanden los datos del martes al resto de los días del grupo A, así como los datos del sábado al viernes, se obtiene lo siguiente:
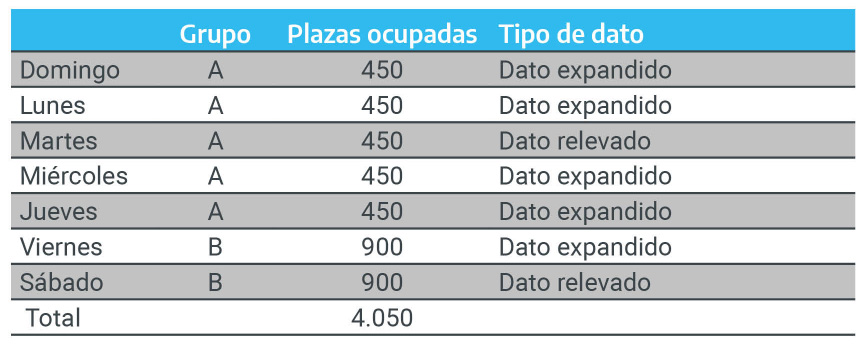
Figura 2.18: Tabla de Grupos
Como puede observarse, a los días domingo, lunes, miércoles y jueves se les asignó la cantidad de plazas relevadas del día martes (450 plazas ocupadas), mientras que al viernes se expandió el dato del sábado (900 plazas ocupadas). Como resultado, el total de plazas ocupadas de la semana X es 4.050.
La EOH es un operativo contínuo desde el año 2004 con una frecuencia de relevamiento mensual y el periodo de referencia de los datos también es mensual. Es decir, todos los meses se le consulta a los establecimientos hoteleros y parahoteleros seleccionados información de la actividad de todo el mes. Diferente es lo que realiza la EOH de España, la cual presenta una frecuencia de relevamiento mensual pero el periodo de referencia es semanal: “la consulta de datos básicos se refiere a siete días seguidos de cada mes, elegidos aleatoriamente, de tal manera que entre todos los establecimientos cubran el mes completo” . Mayor información: Aquí
A su vez, en Argentina, no sólo se le pregunta la cantidad de plazas y habitaciones ocupadas, de nuevos viajeros hospedados, las pernotaciones, sino también la disponibilidad de habitaciones, unidades y plazas y la cantidad de días abiertos en el mes de interés. Esto último es muy importante, por que algunos hoteles no abren sus puertas durante todo el mes, sino para determinadas fechas relevantes (un fin de semana largo por ejemplo) y por ello, la disponibilidad real del hotel se calculará en función de la disponibilidad de plazas/habitaciones/unidades que tiene ese hotel por la cantidad de días abiertos. Dicha información y, en función de los datos declarados de ocupación, se calculan las correspondientes tasas de ocupación mensuales durante todo el año.
2.7.2 Formas de relevamiento
Además de los aspectos desarrollados previamente, otro punto importante en la instancia de planificación del trabajo de campo es la evaluación de cuál será la forma de relevamiento adecuada (telefónica, mediante entrevista personal, auto-administrada), teniendo en cuenta los objetivos, las dificultades propias del relevamiento, el tipo de estudio (censal o muestral), la celeridad con que se necesitan los resultados, los recursos humanos disponibles, la frecuencia de relevamiento, el período de referencia de los datos relevados, etc.
En la Figura 2.19 se presentan las ventajas, limitaciones y requerimientos de cada forma de relevamiento. Cabe mencionar que, a pesar de sus pros y contras, todas son alternativas válidas a la hora de ejecutar el trabajo de campo mientras se respeten los criterios metodológicos básicos que deben guiar el trabajo de campo.

Figura 2.19: Ventajas, limitaciones y requerimientos por forma de relevamiento
2.7.3 Otras consideraciones acerca del trabajo de campo
En relación al personal a cargo de la recolección de datos, como se desprende de la figura anterior, las encuestas pueden ser realizadas por personas que trabajen dentro de la institución y que estén afectadas a distintas tareas, o por encuestadores específicamente destinados a este trabajo. En la mayoría de las jurisdicciones, por razones de disponibilidad de recursos humanos, el trabajo de campo es ejecutado por el mismo personal de las entidades de turismo.
Por último, es preciso llevar adelante un continuo y simultáneo monitoreo del trabajo de campo, dado que permite detectar a tiempo:
si el relevamiento se finalizará en el tiempo estimado;
posibles errores de registro de los datos;
casos de no respuesta.
Si durante el trabajo de campo se detectan casos de no respuesta, y si se tratase de un estudio por muestreo, una alternativa posible sería el reemplazo probabilístico (esto es, con criterios aleatorios) del establecimiento sin dato por otro establecimiento de similares características.
2.8 Procesamiento y análisis de la información
La etapa lógica que sigue al trabajo de campo es la carga de los datos, que consiste en trasladar la información del cuestionario o planilla en papel a la base de datos. En las jurisdicciones que realizan relevamiento telefónico con ingreso directo de los datos en planillas digitales o softwares, la carga se efectúa, lógicamente, en simultáneo al trabajo de campo. En el caso de relevamientos online, muchos software permiten descargar los datos en formato de bases de datos.
Por otro lado, como se mencionó en el apartado 1.1, muchas provincias argentinas suelen recopilar datos de estudios de ocupación hotelera y para-hotelera producidos por los municipios. En varios de estos casos, los equipos técnicos de las provincias han diseñado planillas modelo en las que se propone a cada jurisdicción municipal cargar los datos producidos, con el fin de utilizarla para realizar estimaciones propias, ya sea a nivel local o provincial (agregando datos de las localidades relevadas).
A continuación se presenta un modelo de planilla para la carga de los datos, que puede ser utilizada por los municipios y/o provincias, ya sea para producir datos propios o recopilar datos producidos por terceros. Para seguir en la misma línea, se utilizaron algunos de los establecimientos considerados en el ejemplo de estratificación y selección de muestras al interior de cada estrato (apartado Ejemplo de estratificación y selección de muestras al interior de cada estrato). Asimismo, se asumió que el relevamiento se realiza los días lunes y miércoles, preguntando el lunes por las plazas ocupadas y plazas disponibles del sábado anterior, y el día miércoles por las plazas ocupadas del martes previo.
Figura 2.20: Modelo de planilla para la carga de los datos
2.8.1 Consistencia y validación de la información
Una vez que han sido ingresados los casos a la base de datos, es necesario llevar adelante un proceso de validación16, lo cual implica realizar un análisis de consistencia interna de los datos y de situaciones extrañas o no esperadas en los valores de los datos. Durante la validación pueden detectarse errores y/o advertencias. Un ejemplo de error sería encontrar que la cantidad de plazas ocupadas supere a la cantidad de plazas disponibles17. Por otro lado, una advertencia se podría presentar cuando en un establecimiento se produce una variación notoria en la cantidad de plazas ocupadas, en un período en que se esperaba que ese valor estuviese estancado. Si durante el proceso de validación se detecta algún dato inconsistente o alguna advertencia, lo adecuado es volver a contactar al encuestado para solicitarle el dato correcto en el caso de un error o para constatar si lo que surgió como advertencia es un error o una situación que tuvo lugar realmente.
2.8.2 Tratamiento de la no respuesta
Otra situación que puede presentarse durante el proceso de chequeo de una base es la ausencia de respuesta (o no respuesta) en varias o todas las preguntas de algún caso específico. Si la no respuesta se reduce a algunas preguntas, la solución más atinada es, similarmente al caso anterior, intentar obtener el dato del mismo respondente. Si ello no fuese posible, un procedimiento válido es la imputación.
Imputar significa asignar a las preguntas con no respuesta valores provenientes de casos con características similares a las del caso en cuestión o, en estudios continuos, asignar valores del mismo caso en relevamientos anteriores (en lo posible, de similar período). Por ejemplo, si en un relevamiento continuo, un establecimiento X no informó la cantidad de habitaciones ocupadas en un período específico, y no se logra obtener el dato faltante por parte del informante, se puede optar por imputar el número de habitaciones ocupadas declarada por ese mismo establecimiento en un relevamiento previo que sea similar al evaluado, o bien aplicar el porcentaje de ocupación de uno o varios establecimientos similares (donante). Otra opción, quizás más sencilla que las anteriores (y siempre y cuando no haya sido posible obtener respuesta de los responsables de los alojamientos), es asignar a los establecimientos sin respuesta el valor promedio del estrato al que pertenecen. Por ejemplo, si en el estrato “Hoteles 1 y 2 estrellas, menos de 200 plazas” hay dos hoteles que no aportaron datos, y si en dicho estrato se obtuvo un \(74\%\) de ocupación, este procedimiento supone asignar a los establecimientos sin respuesta un \(74\%\) de ocupación.
2.8.3 Ponderadores o factores de expansión
Otro procedimiento clave, previo al análisis de los datos, es la construcción de ponderadores o, lo que es lo mismo, factores de expansión, que tienen una doble función y resultan ineludibles en todo estudio muestral:
- Asignar a los casos relevados el mismo peso que tienen en el universo o población (calibrar).
A menudo suele ocurrir, como producto de problemas inherentes al trabajo de campo (p.e., la no respuesta) o del mismo diseño muestral (en los estudios por muestreo), que algunos grupos o estratos (por ejemplo, clase, categoría, región, etc.) presenten en la muestra, o en el conjunto de casos relevados, un peso relativo diferente al que tenían en la población bajo estudio. En otras palabras, ya sea intencionalmente o como fruto de dificultades no controladas durante la fase de relevamiento, puede llegar a distorsionarse el peso de algunos grupos o estratos, quedando sub o sobre-representados en comparación con la población de origen. Por ejemplo, si en la población bajo estudio las plazas de los hoteles de 2 y 3 estrellas tienen una participación del \(30\%\), y en la muestra alcanzan un \(20\%\), esto significa que en la muestra este grupo de establecimientos se encuentra sub-representado (tiene un peso relativo inferior al que presenta en la población). Ante esta situación, se hace necesario calibrar o corregir la muestra (o conjunto de casos alcanzados), con el fin de devolver a cada grupo o estrato la participación relativa que tenían originalmente en la población bajo estudio. Esta será una de las funciones que tendrá el ponderador: multiplicar a cada uno de establecimientos de 2 y 3 estrellas relevados por un valor (ponderador), que permita transformar ese \(20\%\) muestral en un \(30\%\). En este caso, la fórmula para obtener el ponderador es dividiendo \(30\%\)/\(20\%\)=\(1,5\). Por lo tanto, a cada establecimiento de ese estrato hay que multiplicarlo por \(1,5\) para alcanzar el peso relativo original (\(30\%\)). Por otro lado, es probable que, si el estrato de 2 y 3 estrellas está sub-representado, otro estrato esté sobre-representado. Por lo tanto, los casos de este último deberán ser multiplicados por un valor inferior a 1, para “aplastar” el peso alcanzado por ese estrato en la muestra.
Para finalizar, se citará un ejemplo en el que se mostrará el peso original de cada grupo o estrato en la población y el peso alcanzado en la muestra; luego, se describirá el proceso de construcción de ponderadores para devolver, a cada estrato, el peso que originalmente exhibía en la población (en otras palabras, calibrar la muestra).
Se supone que la población bajo estudio está compuesta por hoteles de 1, 2, 3, 4 y 5 estrellas, agrupados en tres estratos, como se aprecia en la siguiente tabla.
Estrato 1: hoteles de 1 estrella
\(N1\)= \(15\);\(w\) (\(pow\))=\(0,3\);
\(n1\)= \(5\); \(w\) (\(muestra\))=\(0,2\).
Estrato 2: hoteles de 2 y 3 estrellas
\(N2\)= \(25\); \(w\) (\(pow\))=\(0,5\);
\(n2\)= \(10\);$ w$ (\(muestra\))=\(0,4\).
Estrato 3: hoteles 4 y 5 estrellas
N3= \(10\); \(w\) (\(pob\))=\(0,2\);
n3= \(10\); \(w\) (\(muestra\))=\(0,4\).
Notaciones:
\(N1,2,3\)=tamaño del estrato en la población
\(n1,2,3\)=tamaño del estrato en la muestra
\(w\) (pob)=peso del estrato en la población
\(w\) (muestra)= peso del estrato en la muestra.
En la tabla se observa que, en la muestra de establecimientos, los pesos que originalmente tenían cada estrato se han distorsionado. Cabe aclarar que, en algunos operativos, como es el caso de la EOH, el peso del estrato compuesto por hoteles de 4 y 5 estrellas se distorsiona intencionalmente, ya que se realiza un censo dentro del estrato. De todas formas, para que los resultados no se vean afectados, es preciso devolver a dicho estrato el peso original. Por lo tanto, para que cada uno de los estratos vuelva a contar con su peso original, se procede a construir los ponderadores de cada uno:
Estrato 1 - ponderador 1: \(0,3/0,2=1,5\)
Estrato 2 - ponderador 2: \(0,5/0,4=1,25\)
Estrato 3 - ponderador 3: \(0,2/0,4=0,5\)
En consecuencia, a los casos del estrato 1 se los debe multiplicar por \(1,5\); a los del estrato 2 por \(1,25\); y a los del estrato 3 por \(0,5\)
Los cálculos realizados son una simplificación, ya que además de calibrar, un ponderador también debe cumplir la función de expandir los resultados de la muestra al total poblacional, tal como se describe debajo.
- Expandir los resultados obtenidos sobre los casos relevados a todo el universo (factor de expansión inicial). Esto es, si el universo contempla 100 establecimientos y se encuesta a 20 de ellos, los resultados de cada establecimiento relevados deberán multiplicarse por 5 (\(100/20=5\)) para representar los valores del universo bajo estudio. En el caso de un muestreo estratificado, este coeficiente debe ser calculado para cada estrato.
Nuevamente, si bien su función es doble, esto no significa que haya que calcular un ponderador para expandir y otro para calibrar. Por el contrario, un mismo ponderador cumple esta doble tarea. En definitiva, los factores de expansión son números (fraccionarios o enteros) por los que se multiplican a los casos reales para lograr el doble propósito que se describió arriba. En general, en los estudios por muestreo se suele calcular un factor de expansión o ponderador inicial en la etapa de selección de la muestra, es decir previo al trabajo de campo. Luego del trabajo de campo, si se produjesen desajustes de los casos (sobre o sub representación de los casos), se procede a ajustar el factor de expansión inicial, para, además de expandir, calibrar los resultados.
Cabe mencionar que los procedimientos para el cálculo de ponderadores presentados son aplicables a muestras seleccionadas con las técnicas MAS o MSYS, en las cuales cada uno de los elementos tiene idéntica probabilidad de selección.
Para afianzar las ideas desarrolladas en este apartado, a continuación se describirá el proceso de construcción de factores de expansión para las muestras seleccionadas en el apartado Trabajo de campo
Recuérdese que la muestra final seleccionada fue:
Figura 2.21: Muestra final
En primer lugar, los establecimientos de los estratos “Hoteles 4 y 5 estrellas, menos de 200 plazas” y “Hoteles 4 y 5 estrellas, más de 200 plazas” tienen un ponderador con valor 1, ya que han sido seleccionados todos los establecimientos y, por tanto, no es necesario expandir los resultados que se obtengan a ningún otro establecimiento. En otras palabras, los establecimientos de estos estratos están “auto-representados” . Lo mismo ocurre con el establecimiento del estrato “Hoteles 4 y 5 estrellas, más de 200 plazas”: su ponderador es 1, y por tanto está auto-representado.
¿Cuál es el procedimiento para el cálculo de los ponderadores en resto de los estratos?
La variable que se utilizará para el cálculo de los factores de expansión de cada estrato será “cantidad de plazas disponibles” , ya que en base a la misma se llevó adelante el procedimiento de selección de la muestra. Por tanto, debajo se describen los cálculos para obtener los ponderadores iniciales de cada estrato.
Hoteles 1 y 2 estrellas, menos de 200 plazas:
Cantidad de plazas disponibles totales del estrato: \(587\).
Cantidad de plazas disponibles de la muestra: \(238\).
Ponderador: \(587/238=2,46638\)
Hoteles 3 estrellas, Apart hotel y Boutique, menos de 200 plazas:
Cantidad de plazas disponibles totales del estrato: \(1.056\).
Cantidad de plazas disponibles de la muestra: \(706\).
Ponderador: \(1.056/706=1,49575\)
Establecimientos parahoteleros:
Cantidad de plazas disponibles totales del estrato: \(811\).
Cantidad de plazas disponibles de la muestra: \(342\).
Ponderador: \(811/342=2,37134\)
Como se ve, en el estrato “Hoteles 1 y 2 estrellas, menos de 200 plazas” el ponderador tiene un valor de 2,46638. Si a las plazas de cada establecimiento seleccionado en la muestra (de este estrato) se las multiplica por este valor, y luego se las suma, se obtiene eltotal de plazas del estrato: 587.Lo mismo ocurre con los otros estratos. Para que se comprenda gráficamente esta idea, en la tabla que sigue se realiza la operación mencionada para cada estrato.

Figura 2.22: Ponderadores
2.9 Obtención de resultados
Una vez finalizado el proceso de validación y construidos los factores de expansión, se está en condiciones de calcular los indicadores que respondan a los objetivos de investigación.
A continuación se presentan algunas alternativas de cálculo de los principales indicadores que usualmente se pretenden estimar a través de los relevamientos de alojamientos turísticos.
Cabe indicar que por razones de simplicidad, los “totales” que se mencionan surgirían, si se tratara de un estudio muestral, de los resultados ya expandidos.
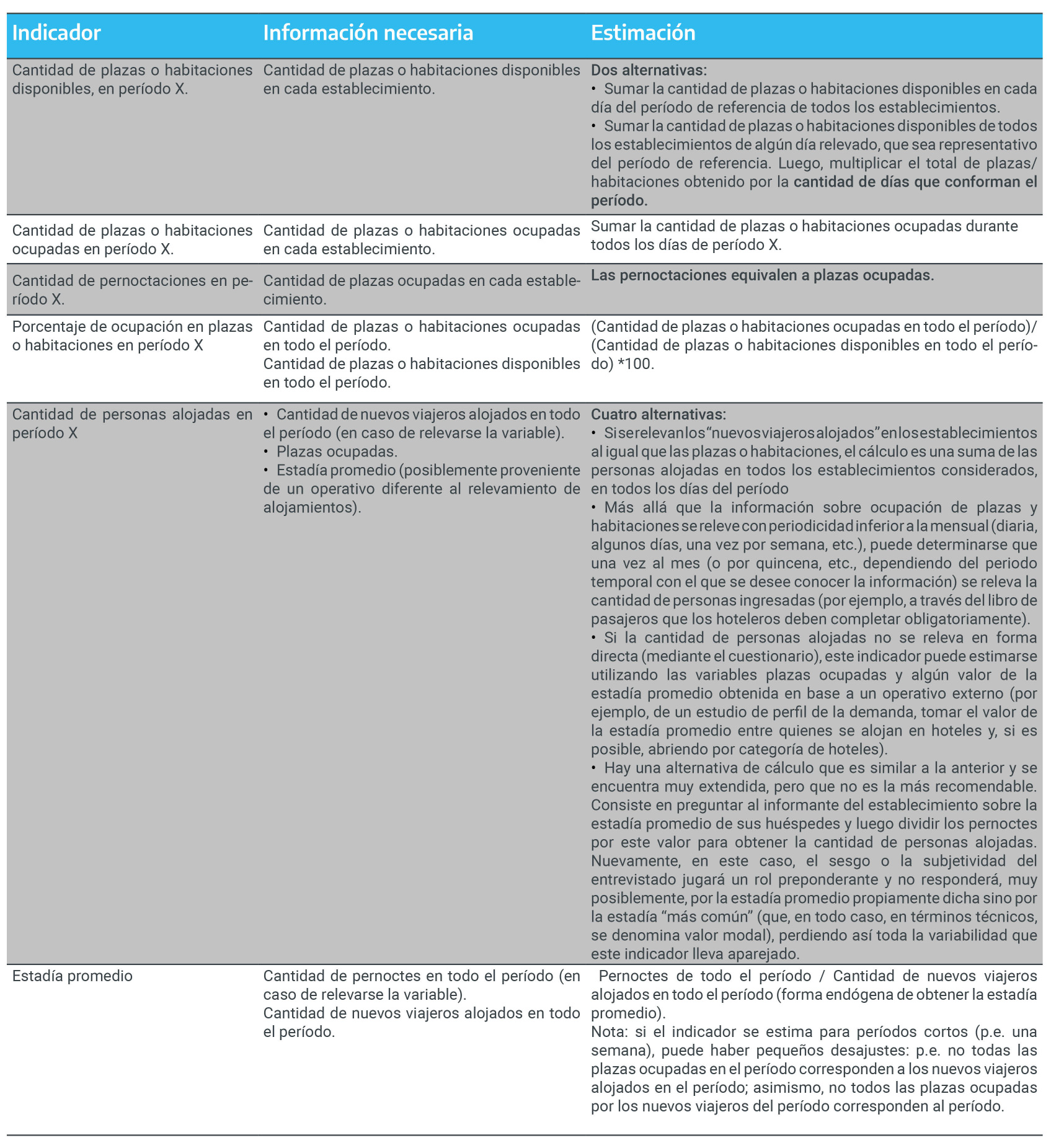
Figura 2.23: Indicadores, información necesaria para su construcción y procedimiento de estimación
Para concluir este apartado, se retomará el ejemplo aplicado en los apartados 2.5.2.8 y 2.9.3 para el cálculo de los indicadores “cantidad de plazas ocupadas (o pernoctaciones)” y “porcentaje de ocupación en plazas”.
Cabe recordar que el objetivo de la Provincia X es obtener resultados para el total de la Localidad Y, sin realizar aperturas por estrato. Sin embargo, para obtener los resultados agregados, es preciso realizar previamente algunos cálculos en cada uno de los estratos.
En cada una de las tablas que siguen, en donde se realizan los cálculos por estrato, se presenta la siguiente información:
“Cantidad de plazas totales”: son las plazas disponibles por establecimiento que figuran en el padrón.
“Cantidad de plazas disponibles en la semana 1 (a)”: es el resultado de multiplicar, para cada establecimiento, las plazas disponibles en el padrón por la cantidad de días del período de referencia. Esto último solo es posible si, en el período bajo estudio, ninguno de los establecimientos presenta variaciones en la oferta de plazas18. En este sentido, lo recomendable es relevar, con una frecuencia establecida, la cantidad de plazas disponibles en cada establecimiento relevado, con el fin de detectar posibles variaciones en la oferta.
“Cantidad de plazas ocupadas en la semana 1 (b)”: es un dato obtenido del propio relevamiento.
“Ponderador (c)”: es el valor que se ha calculado en el apartado 2.9.3, para cada estrato.
“Cantidad de plazas disponibles semana 1 en todo el estrato (d)”: es el total de plazas disponibles del estrato (es decir, considerando la totalidad de los establecimientos) multiplicado por la cantidad de días del período de referencia.
“Cantidad de plazas ocupadas semana 1-dato expandido (e)”: se obtiene multiplicando la cantidad de plazas ocupadas de cada establecimiento por el ponderador del estrato.
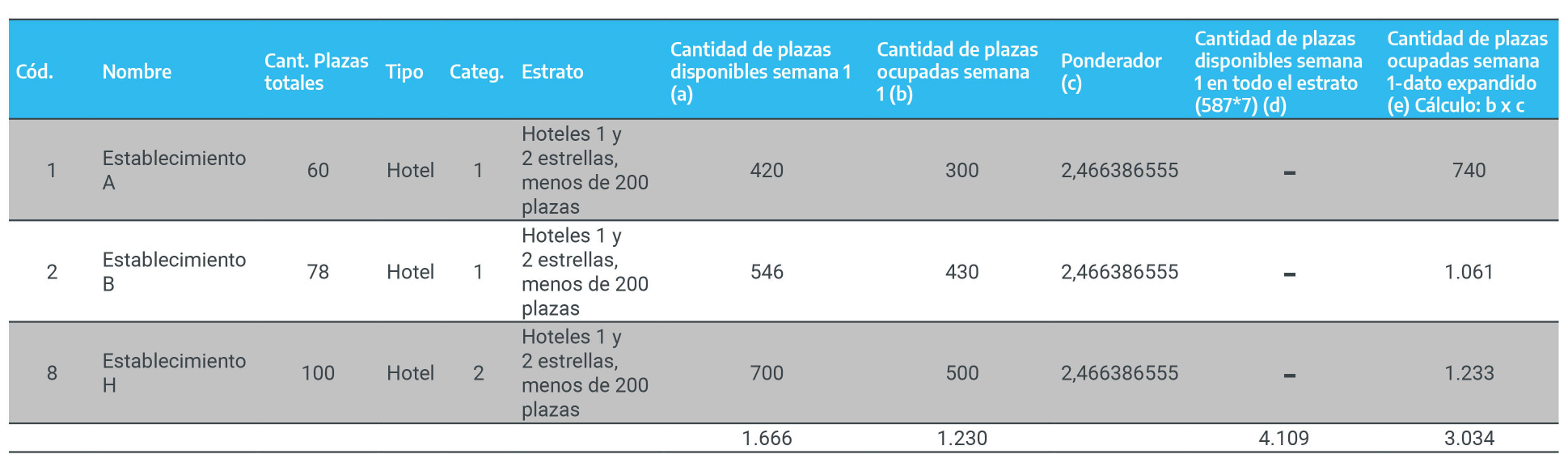
Figura 2.24: Hoteles 1 y 2 estrellas, menos de 200 plazas
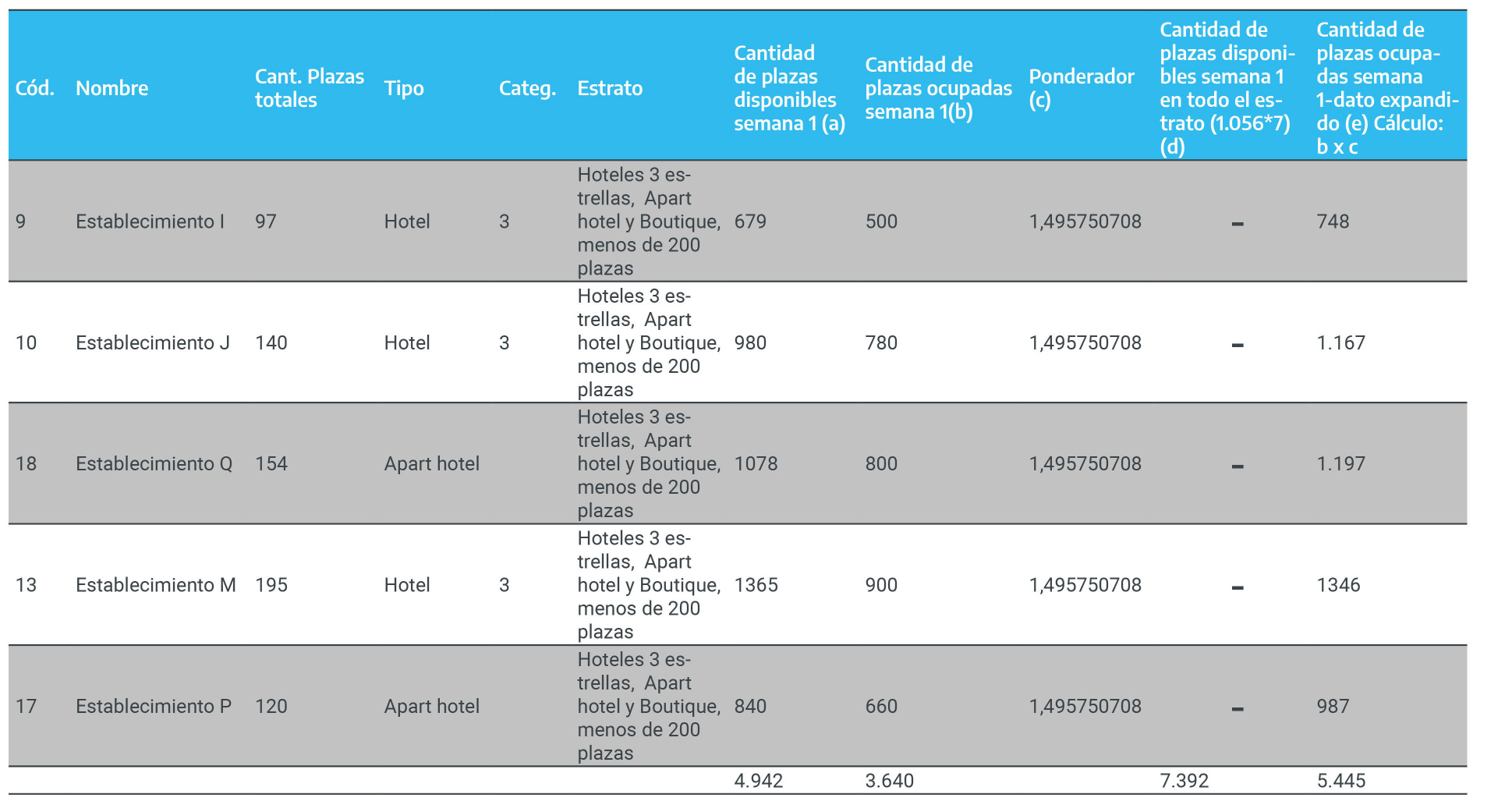
Figura 2.25: Hoteles 3 estrellas, Apart hotel y Boutique, menos de 200 plazas

Figura 2.26: Hoteles 3 estrellas, Apart hotel y Boutique, más de 200 plazas

Figura 2.27: Hoteles 4 y 5 estrellas, menos de 200 plazas
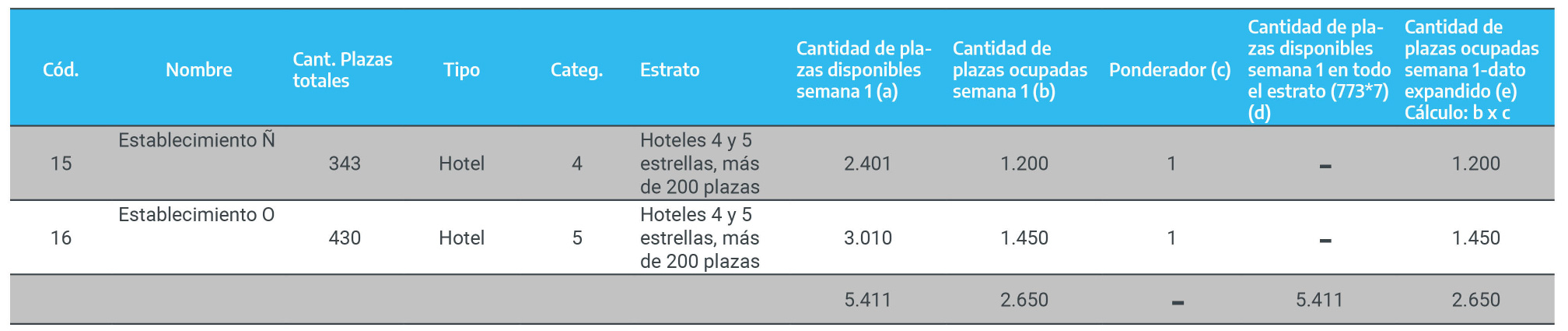
Figura 2.28: Hoteles 4 y 5 estrellas, más de 200 plazas
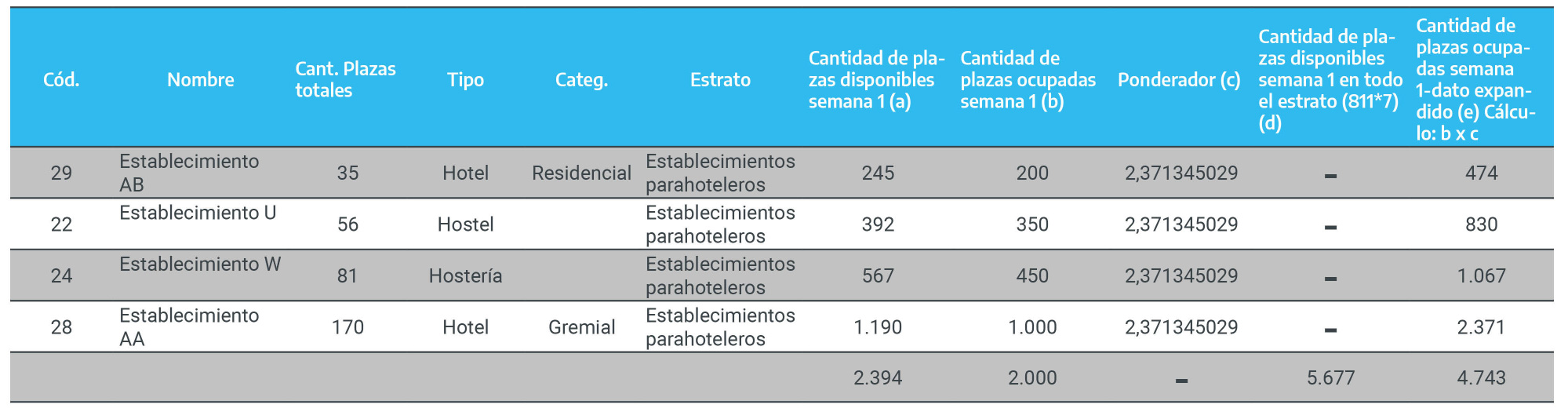
Figura 2.29: Establecimientos parahoteleros
Luego de haber realizado los cálculos previos por estrato, se procede a estimar los indicadores para el total de la Localidad Y.
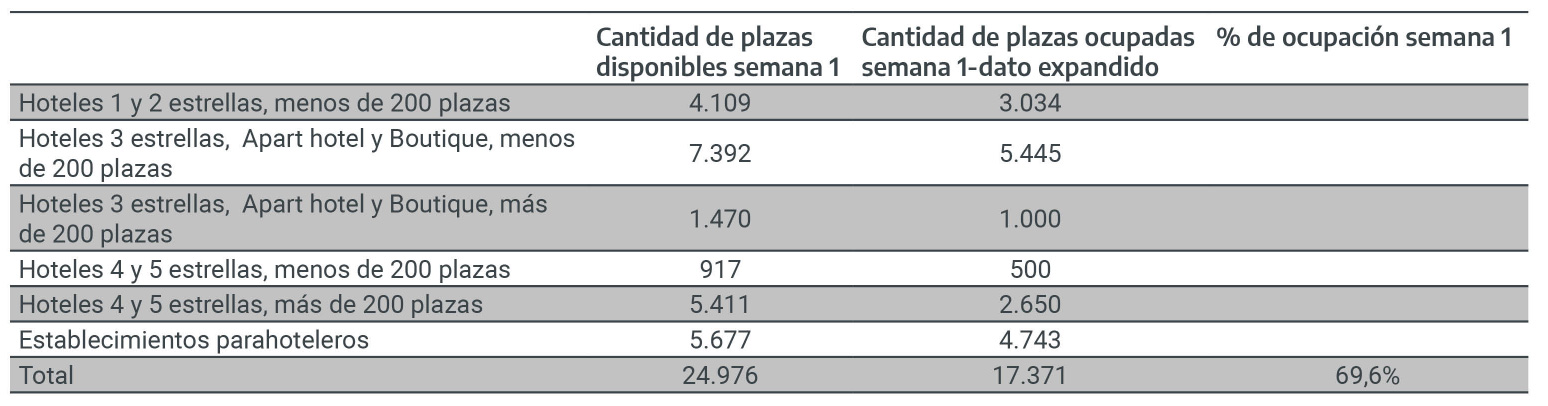
Figura 2.30: Total localidad
Como puede observarse, la cantidad de plazas ocupadas (o pernoctaciones) totales de la Localidad Y, en la semana 1, son el resultado de la suma de las plazas ocupadas de todos los estratos, habiendo aplicado previamente los correspondientes factores de expansión. Por otra parte, el porcentaje de ocupación total, en la semana 1, es la razón entre la cantidad de plazas ocupadas (o pernoctaciones) totales (17.371) y la cantidad de plazas disponibles totales (24.976).
Si bien aquí se plantea indistintamente, algunos autores prefieren utilizar únicamente el término población, dado que consideran que el universo es “un conjunto infinito de datos” , que son aplicados a la población (Hernández Sampieri, Fernández Collado, Baptista Lucio, 1998).↩︎
Programas informáticos de uso muy difundido como el Excel contemplan una función generadora de números aleatorios. No obstante, el “sorteo” puede realizarse de cualquier forma, incluso manualmente, mientras se respete el criterio de completa aleatoriedad.↩︎
Cabe señalar que los estudios censales carecen, por definición, de errores estadísticos. No obstante, existen otro tipo de errores que afectan a los resultados obtenidos, tanto por muestra como por censo y que se denominan “errores no muestrales” o “errores no estadísticos” y, a diferencia de los errores estadísticos es imposible (o harto complejo y muy costoso, en el mejor de los casos) estimar la magnitud de los mismos. El hecho de que muchas veces se realicen estudios por muestra se relaciona tanto con cuestiones operativas (menores costos) como con la posibilidad de reducir los errores no muestrales, al realizar un relevamiento de campo de mejor calidad centrado en pocas unidades, como se mencionó más arriba.↩︎
Como puede apreciarse, el tamaño de muestra total es muy pequeño. En este ejemplo se define tal tamaño solo con fines ilustrativos, más aún considerando que el padrón solo consta de 30 establecimientos.↩︎
Otra variable en función de la cual se pueden calcular los pesos de los estratos podría ser habitaciones disponibles, siempre y cuando las habitaciones sean la (o una de las) unidad/es de análisis.↩︎
Los operativos de algunas provincias/departamentos/municipios, en lugar de emplear cuestionarios en sentido estricto, utilizan planillas, en cuyas filas están registrados los establecimientos a ser relevados y en donde las variables o preguntas están dispuestas en las columnas. Las planillas suelen ser digitales (en Excel o Access) o en papel. Una de las ventajas de las planillas digitales es que permiten omitir el paso de “carga de datos” . Este formato de instrumento de medición suele ser utilizado en los relevamientos telefónicos.↩︎
En establecimientos no hoteleros como complejos de cabañas, apart hoteles, complejos de departamentos y campings, ya no se mide la ocupación y disponibilidad en habitaciones, sino en la misma unidad. En los complejos de cabañas, la unidad es la misma cabaña; en los apart hoteles y complejos de departamentos, el departamento; en los campings, la parcela.↩︎
La validación no es exclusiva de esta etapa y es preciso que se definan pautas de consistencia para las diferentes etapas del campo (cuando se completa el formulario, cuando el mismo es recepcionado por un supervisor, etc.). No obstante, en esta etapa las herramientas informáticas permiten validar la información en forma certera, pudiendo incluir además información externa (por ejemplo, si algún valor se aleja sustancialmente de la media del estrato o de información suministrada anteriormente por el mismo establecimiento, casos en los que es preciso chequear que la información brindada sea la correcta).↩︎
Sin embargo, puede ocurrir que un establecimiento, en períodos de alta demanda, utilice sus plazas supletorias. En esos casos, se debe corregir el número correspondiente a las plazas disponibles.↩︎
Recuérdese que en algunas jurisdicciones la cantidad de plazas y/o habitaciones ofrecidas pueden sufrir variaciones (aumentos o bajas) a lo largo del año.↩︎